こんにちは、delyコマース事業部サーバーサイドエンジニアの小川です。
最近クラシルにて、ネットスーパー機能のリリースができました! (以下 クラシルネットスーパー)
入社して1年くらいたちますが、とってもエキサイティングな毎日を過ごしています。
この記事は「dely #1 Advent Calendar 2020 - Adventar」の24日目の記事です。
前日は仁多見さんの記事でした!↓
思った以上に大変だったクラシルでの Scoped Storage 対応 - クラシル開発ブログ
はじめに
みなさんはElasticsearchを利用して、開発中のサービスに検索機能を導入したことはありますでしょうか。 今や様々なサービスで利用されているかと思います。
クラシルネットスーパーでは、キーワード検索以外の部分でもElasticsearchを活用しています。
レシピに紐づく食材を取得したり
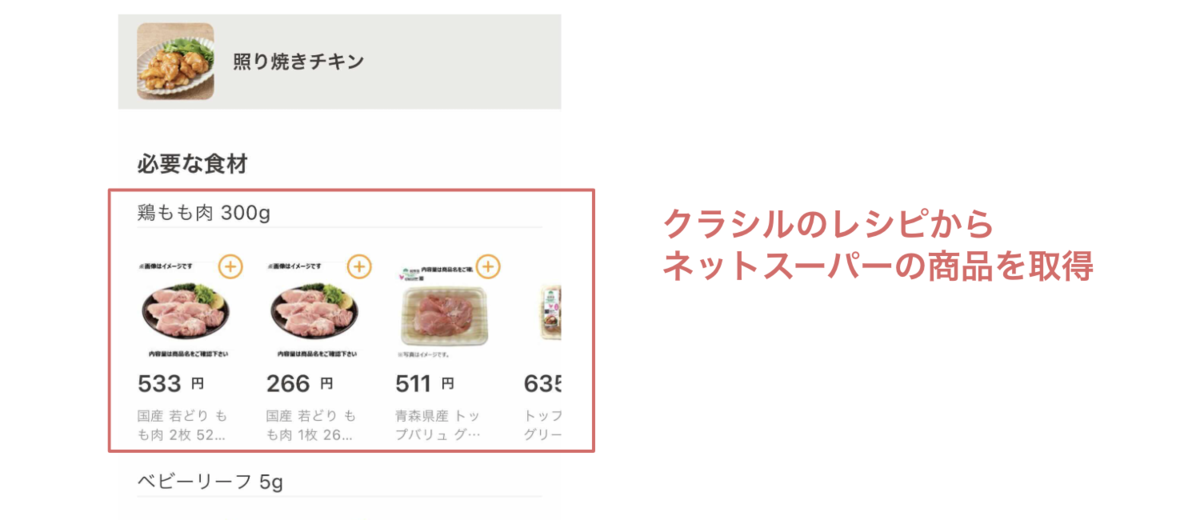
商品を分類・識別したり

普通だったら、玉ねぎカテゴリに玉ねぎの商品を紐付ける運用をすると思いますが、 ネットスーパーの商品は1店舗当たり何万件も商品があり、それが日々入れ替わるので上記の運用が現実的ではありません。
商品の分類・識別の自動化が必須だったので、それを今回は自然言語ベースで行いました。 分類・識別や一般的なキーワード検索のどちらも行える、Elasticsearchがとても相性よかったです。
記事メディアとはまた違った検索を提供する特徴的な事例だと思いますが、 検索エンジンの最適化はコツコツとやっていくことがマストです。
最適化についてどんな機能があるか、また運用のポイントなどをまとめていこうと思います。
- Elasticsearchについて基本だけは知っているけど使ったことない方々
- 検索最適化したいけどやり方がわからない方々
の参考になれば幸いです!
最適化の際に必要なElasticsearchの知識
スコアリングの式を知る
Elasticsearchは特定のクエリに対して、類似度を測りスコアリングしています。
スコアリングは主に、tf-idf を利用して算出されています。

参考:https://lucene.apache.org/core/8_6_0/core/org/apache/lucene/search/similarities/TFIDFSimilarity.html
q がクエリ、d がドキュメント、 t がターム(ドキュメントの内容を形態素解析した得られた単語)として見てみましょう。
根拠を持って検索最適化を行うためには、スコアリングの式についての理解が必須です。
同義語について知る
Elasticsearchでは「同義語」をanalyzerに設定することができます。
analyzerの概念図
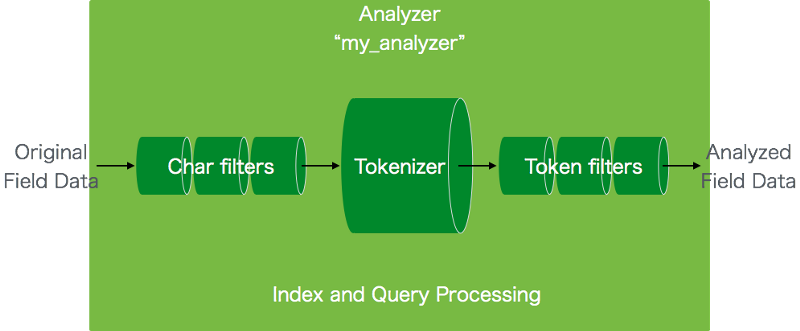
例えば、表記揺れやタイポなどは同義語として設定し、同じものとみなす独自のanalyzerを作成することができます。 例 (トマト,とまと,tomato)など
同義語はanalyzerの概念図のToken Filtersのレイヤーに属します。
以下の図は、同義語の概念について表しています。
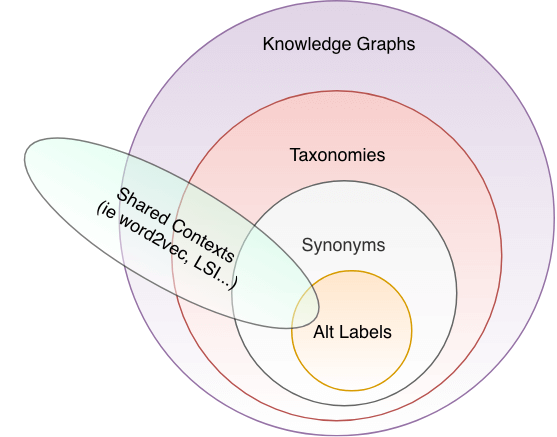
内部のユースケースは、外部のユースケースより単純です。 外部に行くにつれ複雑になりますが、検索エンジンとしての洗練度・パワーが増します。
様々な「同一性」に対して同義語を使うことは不正解ではありませんが、 これらを理解せずに無作為に同義語の設定を行うと、予期せぬ挙動をする検索エンジンが爆誕します。
同義語はとても強力です。 うまく使いこなせば、様々なユースケースに対応できる検索エンジンができるでしょう。 しかしうまく使いこなせないと、気付いた時には運用の難易度がとても高い検索エンジンが誕生してしまうかもしれません。
参考:https://opensourceconnections.com/blog/2018/12/07/synonyms-by-any-other-name-part-1/
さらに精度を高めたい
他にもfunctionクエリやword2vecなどを組み合わせて最適化を行うことができます。 実は画像検索でさえできてしまいます。
詳しい説明は省きますが、そう言った手段もあることを把握しておくだけでとても有益です。
個人的にはword2vecについて興味を持っていて、より有益に使えないかなとソワソワしています。手段の目的化はヨクナイ
最適化の運用・設計のポイント
検索最適化の正解を明確にすること
これは意外と大切です。最初にざっくりでいいので、「想定されるクエリ」と「クエリに対する理想の検索結果」を整理しておきましょう。
例えばネットスーパーで言うと、
ユーザーは「トマト 2個入り」や「トマト 〇〇県産」とは検索しないと想定します。 おそらく「トマト」と検索して出た結果の中から、目当ての「トマト」を選択してカートに入れるでしょう。
となったとき、トマトに付随する「2個入り」や「〇〇県産」と言う単語は、無視できる事になります。 余計な単語は無視することが検索精度向上には大切です。
また、「トマト」と検索した時は、「トマトジュース」や「トマトケチャップ」が結果に出ることは望ましくありません。 「トマトジュース」が欲しいユーザーは「トマトジュース」と検索するからです。 何も最適化せずにElasticsearchを使うと、「トマト」で「トマトジュース」なども出てきてしまいそうですね。
以下のように検索最適化の正解を明確にすることが大切です。
- 想定されるクエリ:トマト
- クエリに対する理想の検索結果:原体のトマト(トマトジュースや、ケチャップはでない)
それにより、
- 「2個入り」や「〇〇県産」と言う単語は、無視できる。
- トマトジュースなどが出てこないようにするにはどういったらいいか
と言う事項を初めから考慮に入れられるようになります。
最適化の作業の難易度・影響範囲・作業量のバランス
検索最適化の正解が明確になって初めて、最適化の作業が始まります。
- 想定されるクエリ:トマト
- クエリに対する理想の検索結果:原体のトマト(トマトジュースや、ケチャップはでない)
を達成するためにたくさんのアプローチがあると思います。最適化の手法に正解はありません。
どのアプローチを選択するかの判断基準として、「難易度・影響範囲・作業量のバランス」を見ると良いです。
アプローチ①

プロダクトの初期においては必要なアプローチかと思います。
例えば、
- 検索クエリが複数渡された場合、or検索だったのをand検索にする
- タイトルとディスクリプションでスコア計算の重みが同じだったのをタイトル重めに調整する
- ストップワードを追加する
などです。
初期はリソースが少ないかつ、影響範囲についてあまり考えなくても良い場面(リリース前など)があると思います。
100点の検索精度ではなく、70~80点くらいの検索精度を目指せれば良いかなと個人的に思います。
アプローチ②

アプローチ①の手法でだいたいの精度が出てきたら、移行して良いと思います。
1つ例をあげると、前述した同義語の概念のうち、Alt Labelsレベルの同義語の登録であれば、誰でもできるかと思います。 運用や設計次第ではもっと高レベルの最適化を専門知識なしに行えるかもしれません。
ここで大切なのは「いかに影響範囲を狭くできるか」になります。
チューニングするたびに現状の検索結果に影響してしまうと、 一方の精度は伸びるけど一方は落ちてしまうなんていうことになりかねません。
着実に70~80点から100点に近づけていける運用が組めると良いと思います。
結局は
プロダクトのフェーズ・特性・リソースなど様々な面から選択していくと良いと思います。
個人的には、「特定の分野における自然言語は限られている」かつ「長期的運用が必要なものが属人化するとヤバイ」と考えているので、 よほどの事がない限り、早い段階で作業内容がストックする前提で、アプローチ②が行えるような設計・運用を試みます。
最後に
以上Elasticsearchのポイントについてざっとまとめてみました。
クラシルネットスーパーでは、割と綺麗な運用で色々な要件を達成できました。 ネットースーパーの商品に手作業でラベルをつけなくても、分類・識別できるようになるのは大きいです。
技術に使われるのはなく、技術を使いこなすことが大切ですね。
レシピ連携機能を作る時、検索について何も知らない自分が弊社CTOに、 「レシピの食材とネットスーパーの商品を手作業で紐付けてくしかない」と言った時に、「ぼくたちがこれをトマトだと判別するのもアルゴリズムだから」と言われて一蹴されたのはとても昔に感じます。
明日はそのCTOである、たけさんの記事です。 お楽しみに!
delyではエンジニアの採用をひたすらやっていますので、興味ある方はぜひのぞいてみてください!