
はじめに
クラシルSREのkashと申します。
クラシルでは検索エンジンとしてElasticsearchを様々な用途で使用しています。 ElasticsearchのクラスタはAWSのEC2上で構築・運用されていましたが、多くの課題が溜まっていたことから、バージョンアップおよびElastic Cloudへの移行を行いました。
本記事では新構成や移行後に起きた問題についてご紹介します。
移行が必要となった背景
AWSのEC2上で構築されていたクラスタは久しくバージョンアップが行われておらず、インスタンスタイプも旧世代が使われていました。また、インデックスごとにS3へのバックアップ用にLambdaが存在していたり、そのLambdaがEOLになっているなど、運用維持が困難な状態でした。
このような状況があったため、インフラ面をSREが担当しつつ、Ruby側の修正はサーバサイドチームの協力ももらいながら、1ヶ月程度かけて新しい構成への移行を行いました。
Elastic Cloudへの移行およびv7へのバージョンアップ
旧構成について
構成図
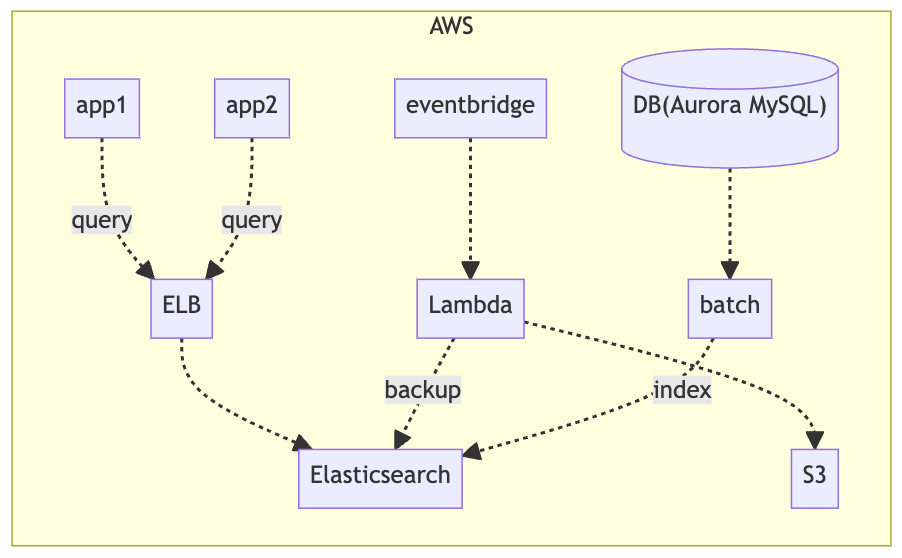
大幅に簡略化していますが、アプリケーションはいくつかのサービスとして分割されており、ECS上で動いています。 またElasticsearchのクラスタはマスタ3台と、数台のデータノードで構成されていました。
なぜElastic Cloudか
AWSのOpenSearchも候補の一つでしたが、最終的にElastic Cloudを選定しました。 他にもElastic Cloud on Kubernetesなどが候補としてありますが、クラシルのアプリケーションはECSで稼動しているため対象外としました。
- elasticsearch-rubyおよびelasticsearch-rails gemへの依存があるため
- AWSにはOpenSearchがありますが、クラシルが依存しているこれらのgemがv7そしてv8以降で使えなくなる可能性を考慮した結果です*1
- クラシル以外の自社サービス(TRILL)で既にElastic Cloudの採用実績があるため
- 運用負荷を軽減するため
- Elastic Cloudであればハードウェアプロファイルの変更やサイズを容易に変えることができます
- クラスタのバックアップも自動で行われており、任意のタイミングの状態を復元することができます
- また、Kibanaの構築やプロキシ設定を自前で行う必要はないのも大きいです
- 最新機能を活用するため
- Elastic Cloudユーザであれば、Elastic社が独自に開発した機械学習モデルであるELSERのような新しい機能を使えるメリットがあります
なぜ移行と同時にアップグレードを行ったか
本来であれば、Elastic Cloudへの移行という大きい変更と、バージョンアップは同時に行いたくありません。
同時に行ったのはElastic Cloudで起動できる最低バージョンがv7だったことが理由の一つです。 移行を何段階かのフェーズに分けて、Opensearch上で今と同じバージョンを起動したりEC2上でアップグレード作業をしてからElastic Cloudへ移行を行う段階的な方法も検討しましたが、大幅に時間がかかることになります。
新環境に加えて旧環境へのインデックスもしばらく動かし続け、いつでも切り戻せる状態にしておくことで、このリスクを許容することにしました。
なぜ最新のv8ではなくv7か
移行時点でelasticsearch-railsのv8対応が進行中という状況でした。
積極的にメンテナンスされているわけではなさそうなため、今後の新しいバージョンでも同様の問題が起きる可能性があり、elasticsearch-railsへの依存を剥がすことの検討が必要になるかもしれません。
サーバサイドの修正内容
サーバサイドチームに協力いただき、Breaking Changesと照らし合わせながら、アプリケーションの改修を行ってもらいました。以下は修正が必要だった変更内容の一部です。
ElasticsearchのClient初期化方法も変わりました。基本的には下記のようなcloud_idを指定する方法で問題ないのですが、クラシルではTraffic Filter(後述)を使用しているため、下のelastic-cloud.comをホストとして指定した初期化方法にしています。Traffic Filterを使用していない場合はデフォルトのfound.ioドメインになります。このあたりは最初戸惑いがありました。
client = Elasticsearch::Client.new( cloud_id: '<deployment name>:<cloud id>', api_key: '******' ) client = Elasticsearch::Client.new( host: "https://*****.es.vpce.ap-northeast-1.aws.elastic-cloud.com", # host: https://*****.es.ap-northeast-1.aws.found.io api_key: '*****' )
辞書や同義語はElastic CloudのExtensionとしてアップロードします。
インデックスのマッピング(kuromoji_tokenizerのuser_dictionary等)もパスを/app/configに変更する必要がありました。ZIPで圧縮する際はdictionariesディレクトリを作る必要がある点もご注意ください。
The entire content of a bundle is made available to the node by extracting to the Elasticsearch container’s /app/config directory. This is useful to make custom dictionaries available. Dictionaries should be placed in a /dictionaries folder in the root path of your ZIP file.
GET /<index name>/_settings?filter_path=**.kuromoji_tokenizer
{
"<index name>" : {
"settings" : {
"index" : {
"analysis" : {
"tokenizer" : {
"kuromoji_tokenizer" : {
"type" : "kuromoji_tokenizer",
"user_dictionary" : "/app/config/<dic>.csv"
}
}
}
}
}
}
}
新構成について
構成図
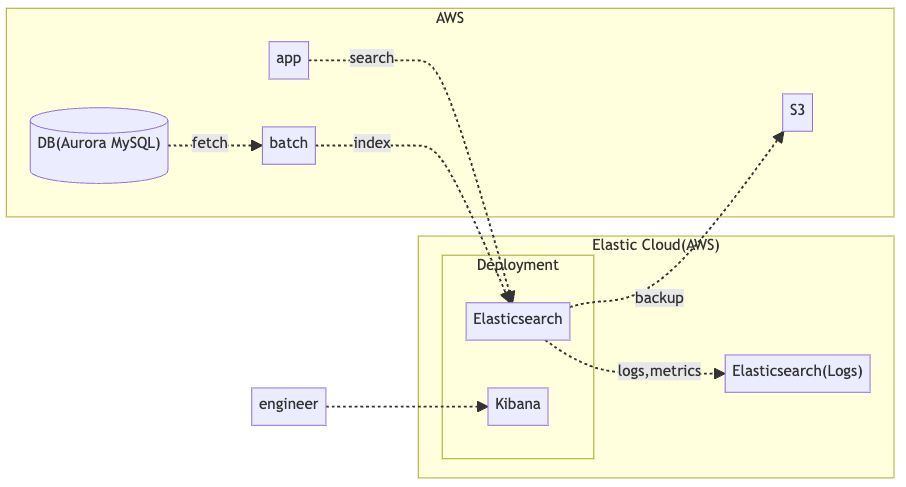
こちらも大幅に簡略化しており、実際にはElastic Cloud上に環境ごとのクラスタを構築しています。
Traffic Filter経由での接続
Traffic Filter for AWSによってクラシルのAWSアカウントとElastic Cloudをプライベート接続しています。インターネット経由での接続に比べて、パフォーマンスが安定しました。AWSの場合、実態としてはPrivateLinkになっています。
パフォーマンス測定はesrallyで行いました。
esrally --pipeline=benchmark-only --target-hosts="https://*****.es.ap-northeast-1.aws.found.io" --client-options="basic_auth_user:'elastic',basic_auth_password:'*****'" --track=<track> esrally --pipeline=benchmark-only --target-hosts="https://*****.es.vpce.ap-northeast-1.aws.elastic-cloud.com" --client-options="basic_auth_user:'elastic',basic_auth_password:'*****'" --track=<track> esrally compare --baseline=<before> --contender=<after>
以下の記事ではTraffic Filterの仕組みが図解されており、わかりやすいのでおすすめです。 www.creationline.com
監視
Datadog
Elasticsearchクラスタの各種メトリクスはDatadogのElastic Cloud連携を使用し、必要に応じて監視を入れています。
ただ、注意点があります。Traffic Filterを有効化すると許可したネットワーク以外は接続できなくなり、Datadogのような外部から監視を行う場合や、更にはエンジニアがKibanaにアクセスするときにも影響します。
タイプがIPアドレスのTraffic Filterを追加してDatadogのIPやエンジニアのIPを適宜追加するか、VPNなど何らかの方法でIPを固定する必要があります。
クラシルでは現時点ではオフィスのIPとVPNからのアクセスを許可し、必要に応じてエンジニアのIPを追加しています。
CloudflareやTailscale等を活用してelastic-cloud.comへのアクセスをPrivateLink経由にする方法もできそうですが、まだ検証できておらず現時点では手動で管理しています。
このような仕様のため、本番稼動中にTraffic Filterを有効化するのは意図せずアクセスを遮断してしまう可能性があるため注意が必要です。これからElastic Cloudへの移行を考えている場合、可能であれば初期からTraffic Filterを使用するかを決めたほうがよいかもしれません。
Elastic Status
Elastic Cloud Statusが公開されているので、メール購読およびDatadogへのRSS登録を行なっています
ログ
メインとなるクラスタのログとメトリクスは他のクラスタに転送しています。以下の画像は例です。
転送先のクラスタはv7にする必要はないため、最新バージョンであるv8にしており、これによってStack Monitoringが使えるようになりました。インデックスごとの検索レートがリアルタイムで分かるため非常に便利です。
ゆくゆくはWatcherのSlack通知を活用したいと思っています。
deprecation
バージョンを上げたことで非推奨の設定もあります。ログはelastic-cloud-logs-*インデックスに格納されており、deprecationに関するログはevent.dataset: "elasticsearch.deprecation"という条件でKibanaのDiscoverで可視化するか、以下のようなクエリで抽出できます。
GET elastic-cloud-logs/_search?filter_path=**.message
{
"query": {
"term": {
"event.dataset": {
"value": "elasticsearch.deprecation"
}
}
},
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
]
}
クラシルでは以下のようなログが発生しており、次のバージョンにアップグレードする前に対応する必要があります。
The [edgeNGram] token filter name is deprecated and will be removed in a future version. Please change the filter name to [edge_ngram] instead
slowlog
インデックスごとにslowlogの設定をしています。
以下の例では直接インデックスの設定を更新していますが、実際にはインデックステンプレートでインデックスパターンに対して指定しています。閾値を0sにすると全てのクエリをログに出すことができるため、開発環境のクラスタでどのようなクエリが実行されているかを把握するために活用していたりします。
PUT /<index name>/_settings
{
"index.search.slowlog.threshold.query.trace": "<threshold>"
"index.search.slowlog.threshold.query.debug": "<threshold>"
"index.search.slowlog.threshold.query.info": "<threshold>"
"index.search.slowlog.threshold.query.warn": "<threshold>"
}
ログはdeprecationと同様で、event.dataset: "elasticsearch.slowlog"で抽出できます。
このログにはクエリの全文が格納されており、KibanaのProfilerにコピペすることでクエリが遅い原因を調査することが可能です。
audit
xpack.security.audit.enabledを指定にすることで、監査ログを有効化でき、ログはevent.dataset: "elasticsearch.audit"として出力されます。記録するイベントの種類やインデックスを限定することもできます。
xpack.security.audit.enabled: true xpack.security.audit.logfile.events.include: access_denied, authentication_failed xpack.security.audit.logfile.events.emit_request_body: true
以下のようにUser Settingsからelasticsearch.ymlを指定しますが、ハマりどころとしては、kibana.ymlにも同様の設定が必要だったということでした。

権限管理
各クラスタの権限管理はElastic Cloudに最近導入されたロール機能を使っています。
カスタムロールなどは現状使えませんが、特定クラスタのadmin、editor、viewer権限を特定の人に対して割り当てることができます。
権限を割り当てることにより、KibanaでLogin with Elastic Cloudを選択することでログインできます。
実はこの機能がリリースされる前はOktaログインを使用することを想定し、検証していました。手順に従って有効化すると、以下のようにログイン画面にLogin with Oktaが表示されます。
このやり方であれば権限を細かく調整できるメリットがあるのですが、クラスタごとにロールを定義する必要があります。現時点ではTerraformで管理しておらず、クラスタが増えると大変になるため、どうしたものかと考えていました。そのような状況でロール機能がリリースされたため、そちらを使うことにしました。
今後は二つを組み合わせることも想定しており、基本的にはElastic Cloudのロール機能でviewer権限を付与し、本番クラスタのみOktaで細かく制御するハイブリッド方式も良さそうと思っています。
S3バックアップ
Elastic Cloudはデフォルトで定期的にバックアップをとってくれています。そのバックアップを使ってクラスタ全体や特定のインデックスのみを復元できるのが非常に便利です。
ただ、クラスタを消すとそのバックアップも当然消えてしまいます。なにかしらの問題があったときのことを考えて、以下の手順に従ってクラシルのAWSアカウント側のS3にもバックアップすることにしました。
Configure a snapshot repository using AWS S3 | Elasticsearch Service Documentation | Elastic
Kibana Spaceのロゴ調整
本番用のクラスタ以外にも開発用のクラスタを起動しています。Kibanaを使っているときに、どの環境のクラスタに接続しているかはURLでしかわかりません。 そのため、開発環境だと勘違いして本番に変更を加えてしまう恐れがあります。
ミスが起きることを完全になくすことは難しいですが、可能性を減らすためにKibanaのデフォルトスペースのロゴを変えて環境が本番(Production)であることに気づきやすくしました。
なお、8.8系ではCustom Brandingという機能が導入され、FaviconやKibanaのロゴも変えられるようです。うまいこと活用できれば本番環境であることを強調できるかもしれません。
www.elastic.co
辞書・同義語の運用
Elastic Cloudでは辞書や同義語ファイルをzipで圧縮して前述したExtensionの仕組みを使って、クラスタに紐づけます。
既存のインデックスで既に辞書を使っている状態で、シンタックスやディレクトリ構造が間違った辞書をアップロードするとローリングアップデートが行われますが、その結果、unassigned shard状態になってしまうため注意が必要です。
慌てて前の辞書を使うようにクラスタの状態を戻しても解消しないことがありました。その場合はRestart Elasticsearchで明示的に再起動することで元に戻りました。
本番環境で直面すると非常に焦る事象のため、辞書の更新は慎重にやる必要があり、開発クラスタで事前に辞書が問題ないことを試すことに加えて、あえて不正なファイルをアップロードしてエラー対応をする流れを検証することをお勧めします。
補足(unassigned shardの調査)
Elasticsearchの運用をしていると、unassigned shardという状態になることは避けて通れません。
Datadogではelastic_cloud.unassigned_shardsでメトリクスを確認できますが、Dev Toolsなどからは以下のクエリで確認できます。
GET /_cat/shards?v=true&h=index,shard,prirep,state,node,unassigned.reason&s=state index shard prirep state node unassigned.reason <index name> 0 p UNASSIGNED ALLOCATION_FAILED
原因調査には/_cluster/allocation/explainのAPIが使えます。
GET /_cluster/allocation/explain
{
"index": "<index name>",
"shard": 0,
"primary": true
}
failed shard on node [xSxiF3YWS1yeShDqWQohbg]: failed to create index, failure IllegalArgumentException[Failed to resolve file: system_core.dic\nTried roots: [Filesystem{base=/app/config/sudachi}, Classpath{prefix=}]]
移行後に起きた問題
移行直後は大きな問題は起きず、めでたしめでたし、で終わるかと思いきや5月前半にアクセス数が突発的に跳ねたタイミングで検索リクエストも急増し、それによって障害を起こしてしまいました。
CPUクレジット枯渇
Sentryから以下のような429: Too Many Requestsエラーの通知が来ました。
rejected execution of ** on QueueResizingEsThreadPoolExecutor[name = instance-00000000/search, queue capacity = 1000, ...
queue_sizeはデフォルトの1000のままになっており、何らかの理由で捌ききれずに検索リクエストがキューから溢れてしまったようです。
原因
突発的なクラシルへのアクセス増によって検索リクエストも増え、その結果クラスタにCPU負荷がかかり、データノードのCPUクレジットが枯渇しました。それによって、パフォーマンスの悪化が発生しました。
事象としてはこちらと同じです。 www.elastic.co
残念ながら、現時点ではCPUクレジットの情報をメトリクスとして取得することはできないとサポートの方から聞きました。Nodes Stats APIではcfs_quota_microsが取得できますが、これはCPUクレジットが「枯渇した後」に変化が起きるため、CPUクレジットが「枯渇し始めた」という兆候を検知することはできないようです。
兆候を検知する方法はいまだに未解決で、CPUクレジットの減少が発生しないような余裕のあるハードウェアプロファイルとサイズで構築するしかないという認識です。
対応
どのハードウェアプロファイルを使用するか、どのサイズ(ストレージ、メモリ、vCPU)を使用するかをワークロードに応じて決定する必要があります。
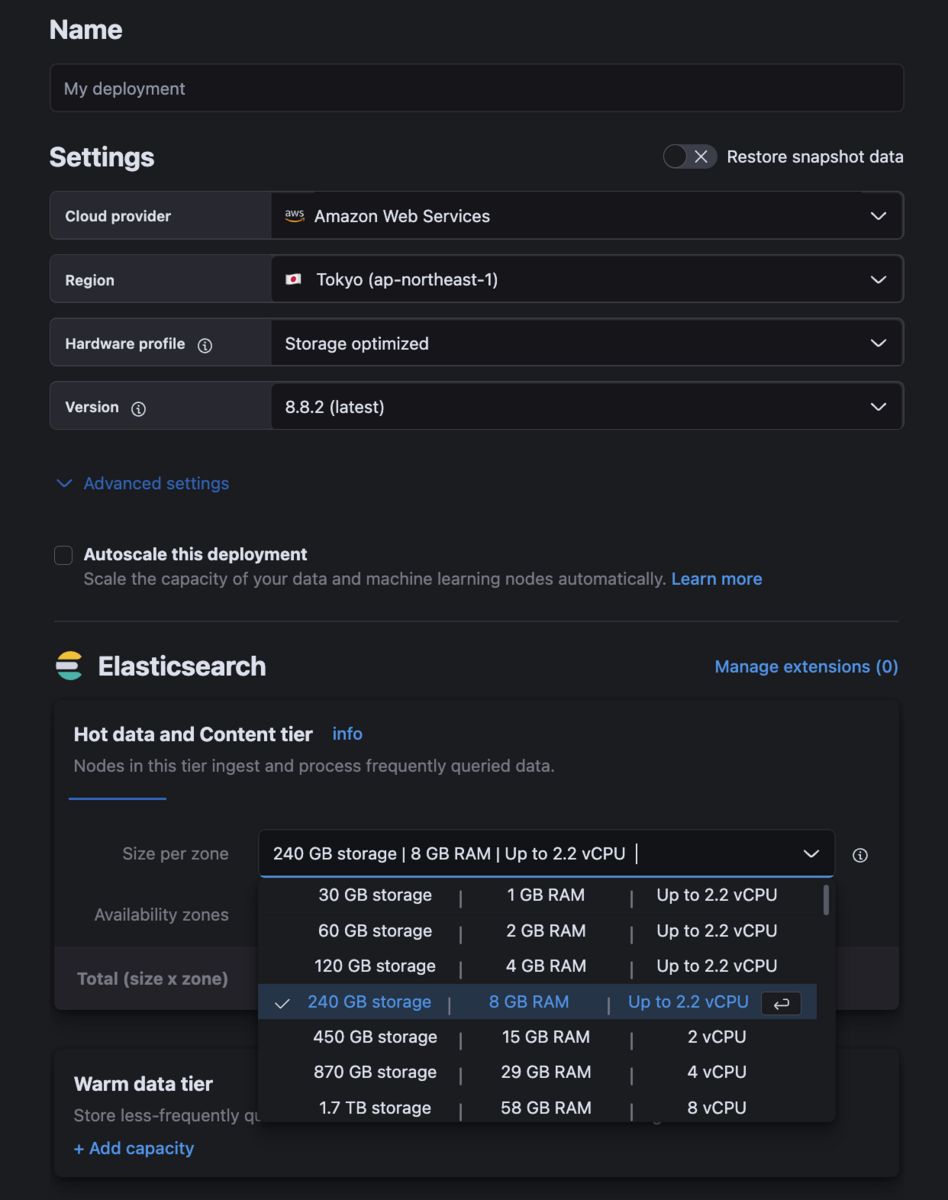
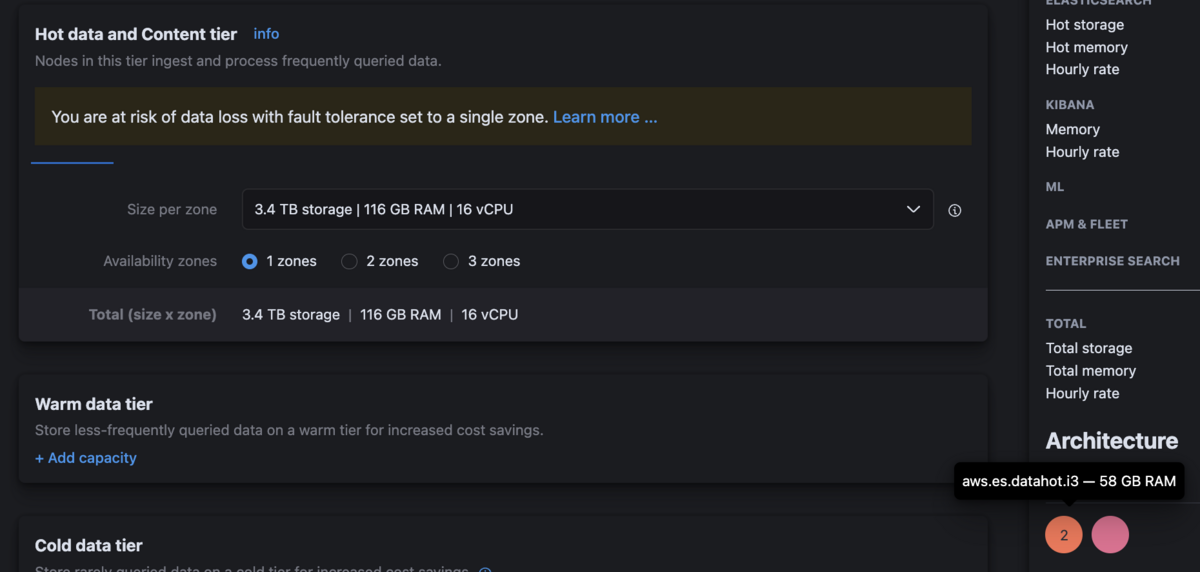
結果的に、ハードウェアプロファイルをStorage Optimizedから、CPU optimized (ARM)に変えることにしました。指定できるサイズは倍々になっていくため、Storage Optimizedのまま次のサイズにすると予算を大幅に超えてしまうため、多少のコスト増でおさまり、CPUにも余裕の出るCPU optimized (ARM)にしました。
基本的にElastic Cloudに変更を加える時はローリングアップデートになり、1台ずつ順にアップデート処理されます。 ただ、落とし穴として、ハードウェアプロファイルの変更はローリングアップデートにはならず、全ノードが一斉にダウンするようです(2023/07時点)。
以下は例ですが、全データノードがNot Routing Requestsになっています。

クラシルのあらゆるところでElasticsearchが使われているため、このままではサービスが全体的に止まってしまいます。 どうしたものか、と悩みましたが、ちょうど直近でメンテナンスを行う予定があったため、そのときにハードウェアプロファイルの変更も行うことにしました。 ちなみに、これはAurora MySQL v2からv3にアップグレードするメンテナンスでした。こちらも別の機会で紹介したいと思います。
問題はメンテナンスまでの数日間をどう凌ぐかです。
Elastic Cloudはデータノードを任意の数にすることはできません。EC2で自前で構築していたときのように、今3台だとして気軽に5台にすることはできません。起動しようとするAZ(availability zone)数でノード数が決まり、例えば3AZを指定すると3ノードになります。
ではデータノード数の上限は3なのか?と疑問に思って試したところ、一定サイズ以上(最低でもメモリが116GB以上)のクラスタを起動しようとするとノード数が増える仕組みのようです。例えば、116GBのメモリを搭載したサイズを指定した場合は58GBメモリのノードが2台、174 GBの場合は3台になる仕組みのようでした。
幸い本番クラスタではWarmノードを2台起動していため、苦肉の策としてこれらを活用することにしました。
Elasticsearchにはdata tierという概念があり、デフォルトではdata_contentが割り当てられています。以下のようなクエリで確認できます。
GET /<index name>/_settings?filter_path=**._tier_preference
{
"<index name>" : {
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
}
}
}
}
}
通常はライフサイクルポリシーでインデックス作成後、指定日数経過したらdata_warm、data_coldなどに遷移させるようにできますが、手動で変えることができます。メンテナンス日までは負荷のピーク時にCPUクレジットを確認するようにし、0になるまえにCPU負荷の高いインデックスの_tier_preferenceをdata_warmにすることで、強制的にノードを変える対応をとりました。ピークを過ぎたら元の値に戻します。
本来のWarmノードの用途ではないので、おすすめはできません。例えば、Warmノードが存在してない状態で指定するとunassinged状態になるため、手動で変えるとリスクがあります。あくまで緊急対応という形です。
結果的に、_tier_preferenceを変える必要があったのは1日のみでしたが、仮に長期間の対応となる場合は厳しいため、その際は一時的なコスト増を許容してハードウェアプロファイルを維持したまま深夜にサイズを上げる対応をとったと思います。
ただ、ローリングアップデートになるか否かについての条件がドキュメントで見当たらなかったため、この仕様が永続的とは限りません。事前に別クラスタ等で検証は必要になりそうです。
結果的にCPU optimized (ARM)にしたあとは、CPUクレジットが問題となることはなくなりました。
今後の展望
v8へのアップグレードはできるかぎり早く行いたいと思っています。 また、バージョンが上がったことで、今までは不可能だったことが可能になりました。以下については実現がいつになるかは分かりませんが、導入できたらいいなと思っています。
- 大きな変更前後の差異を定量的に評価できる仕組みづくり
- v7になったことで、Ranking evaluation APIが使えるようになりました
- v8へのアップグレード等が控えていることもあり、同一クエリにおける検索結果の順位変動を定量的に測る仕組みを整えたいです
- 新バージョンの機能を活用
- Elasticsearchの進化は凄まじく、全てを追えているわけではないですが、魅力的な機能が多く導入されています
- 特に、同義語運用で楽をできる可能性のある検索アナライザーのリロード、Lookup Runtime Field*2、サジェスト機能の改善が見込めるkuromojiのsuggester*3などは活用できそうでした
- また、少し試した程度で分からないことは多いですがELSERを活用することで、よりよい検索体験にできそうです
- sudachiの検討
- クラシルは辞書や同義語の数が膨れ上がっており、管理に課題がある状況です
- メンテナンスが行われているsudachiを活用させてもらうことで辞書や同義語の管理を簡素化できないかと思っています
さいごに
クラシルにおけるElasticsearch v7へのアップグレードおよびElastic Cloudへ移行した結果を振り返りました。 Elatic Cloud移行を検討している方にとって何か参考になることがあれば幸いです。