こんにちは、機械学習エンジニアの辻です。
先日、SageMakerの活用事例で登壇させて頂きました。
machinelearningnighttokyo20181.splashthat.com
機械学習で一番時間の掛かる作業といえば、やはり前処理ですよね。データレイクからデータを取得して、必要に応じて様々なデータストアからデータをかき集めて、加工して、また別のデータストアに入れてと。。。
大量のデータをあっちにやったりこっちにやったりして、もう一体最初は何がしたかったのかさっぱりわからなくなってしまうことがあります。
それに加えて、機械学習では、学習したモデルに対して推論しなければなりませんが、またこの推論結果が必ずしも決定的ではないという課題も含んでいます。
この、決定的ではないとはどういうことでしょうか?
動作が予測可能なもの、つまり、入力したものに対して、常に同じ経路で計算を行い、同じ結果を出力する、こういう振る舞いを決定的と 言います。なのですが、機械学習において、トレーニングで生成されるモデルというのは、その学習データによって、同じ責務を担ったモデルであっても振る舞いが変わってしまいます。
たとえば、同じ100万件のデータについて3クラス分類を行う場合に、昨日推論したときには、クラスAが33万件、クラスBが33万件、クラスCが33万件と綺麗に分類されていたとします。しかし、今日同じデータで推論したらクラスAが80万件、クラスBが15万件、クラスCが5万件と全然違う結果を出力したりして、まさに予測不可能なわけです。
MLストリームパイプライン・プラットフォームの構築
そこで、こんなストリームパイプライン・プラットフォームを構築しました。

アーキテクチャーの変遷
実は、元々データレイクがBigQueryなので、構築の設計当初はGCP Cloud PubSubとDataflowを使って構築しようとしたんですね。親和性が高いし使いやすいので。
まさにこんな感じですよね。
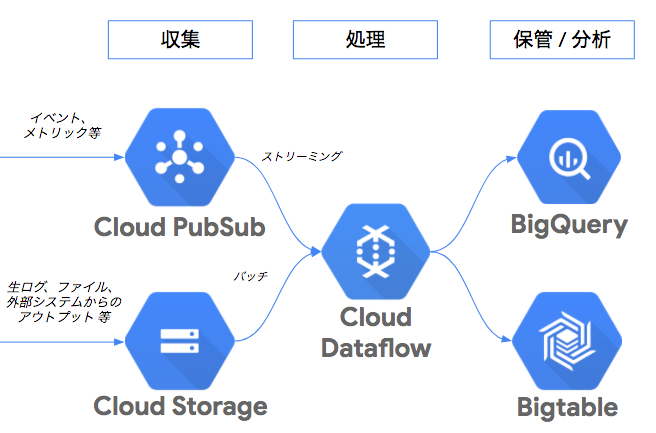
しかし、アプリからCloud PubSubに対して、イベントをパブリッシュするためのSDKが提供されていなかったんです。RESTのエンドポイントは用意されてあるんですが、バッファリングやリトライについてはSDKに任せたいなぁという思いがありました。
そして次に、AWS Batch、Step Functionsを検討しました。AWS Batchは非常に簡単に使えますし、大量のデータでも比較的高速に処理することが可能です。しかしワークロードが固定されてしまうことで柔軟なスケール変更が望めないことと、ワークロードの管理とコードの管理が別々になってしまうので、MLプラットフォームでのDevOpsが一元化できないという課題がありました。
![]()
Step Functionsは、私たちが思い描くイメージにもっとも近い形のワークフローを提供してくれるサービスではありましたが、AWS lambdaのみワークフローステップに指定することが可能ということで、やはりMLプラットフォームのDevOpsが一元管理できない課題を解消することはできませんでした。

しかし、これらのマネージドなサービスについては、必要に応じて今後もどんどん使っていきたいですし、クロスプラットフォームで提供される様々なサービスについても、良いサービスは適材適所で使っていきたい。そんな欲張りな思いもありました。
Kubernetesの採用
そんなわけでKubernetesを採用しました。KubernetesにはJobs、CronJobというのがありましてバッチを起動することができます。特にCronJobはスケジュール起動することが可能です。この機能を利用してストリームパイプラインを組もうと考えたわけです。こうすれば、もちろんクロスプラットフォームでも使えますし、決定的なワークロードのでもいけそうと判断したなら、GCP Cloud Dataflow、AWS Batch、Step FunctionsをCronJobから呼び出して使うといった恩恵も受けられます。現状でもコンテナ内から、AWS GlueのELTジョブに対してpySparkのスクリプトに投げて処理を移譲させたり、AWS Athenaのクエリに計算を任せたりと活用しています。
また、機械学習の非決定という課題ですが、推論結果のサイズによって次の処理で利用するインスタンスのサイズを変えたり、スケールアウトしたりと柔軟な対応が可能となります。
そしてもう一つ、Kubernetesを採用するに至った大きな理由がありました。
Amazon SageMakerの活用
それが、Amazon SageMakerの活用です。
Amazon SageMakerは、機械学習モデルをあらゆる規模で、迅速かつ簡単に構築、トレーニング、デプロイできるようにする完全マネージド型プラットフォームです。SageMakerが提供するビルトインアルゴリズムと、DeepLearningフレームワークはすべて、コンテナでトレーニングJOBが起動できます。つまり、トレーニングJOBというコストの大きな処理をコンテナに移譲させることができるので、ワークロードのインスタンス自体は比較的小さくて済むということなんです。

Kubernetesの運用
kubernetesの運用の中でいくつか工夫している点がありますので、少しご紹介したいと思います。
argo
1つ目は、argoの導入です。argoはワークフローを細かくデザインできるだけでなく、直列処理、並列処理もYAML一つに記述することができるのでとても便利です。管理画面を立ち上げてワークフローが可視化できるのもいいですよね。

kubewatch
2つ目はkubewatchの導入です。これにより、jobの開始と終了、エラーなどについては、こんな感じでkubewatchを通してicebergさんが知らせてくれてます。

DataDog
そして3番目はDataDogの導入です。DataDogエージェントでPodの状況の監視を行っています。複数のnodeの状況を一元的に監視できるのでとても助かっています。
waterコマンドの開発
そして4つ目として、waterコマンドというのを開発しました。
kubernetesやminikubeなどコマンドがたくさんあって運用する上で把握するのが大変ですよね。argoの導入でargoコマンドまで増えてもう覚えきれません。そこでwaterコマンドで必要なコンテキスト単位にコマンドをまとめることで、コマンドのユーザビリティの向上に取り組んでいます。
installerでwater コマンドでインストールします。

Usageが表示されます。

デプロイコマンド
こんな感じで新しいプロジェクトの作成からデプロイ、Podの編集などもwaterコマンドで一元的に統一的な操作が可能になっています。(全部ではないんですけど。。)
今後のロードマップ
現在、パイプラインの制御やPodのUp/Downについては、専用のPod(Control Room)を立てて制御を行ってるのですが、これをAmazon MQを使ってQueueによるイベントドリブンな設計を検討しています。
Amazon MQ
必要に応じて学習エンジンも適材適所使っていきたいと考えています。
Amazon SageMaker
GCP AutoML
GCP ML Engine
最後に
delyでは今回紹介しましたMLストリームパイプラインを格好良くグロースしてくれるエンジニアを募集しています!