
はじめに
あけましておめでとうございます!
クラシルバックエンドエンジニアの加藤です。
クラシルでは2022年4月から一部ユーザーに向けてパーソナライズされたフィードをリリースしました。
(以降、パーソナライズフィード)
パーソナライズフィードではSnowflakeを活用してレコメンドをReverse ETLを行い実現しました。
今回はアーキテクチャの説明と課題・今後の展望について紹介します。
パーソナライズフィードについて
ホーム画面に表示される一連のコンテンツのことを指します。
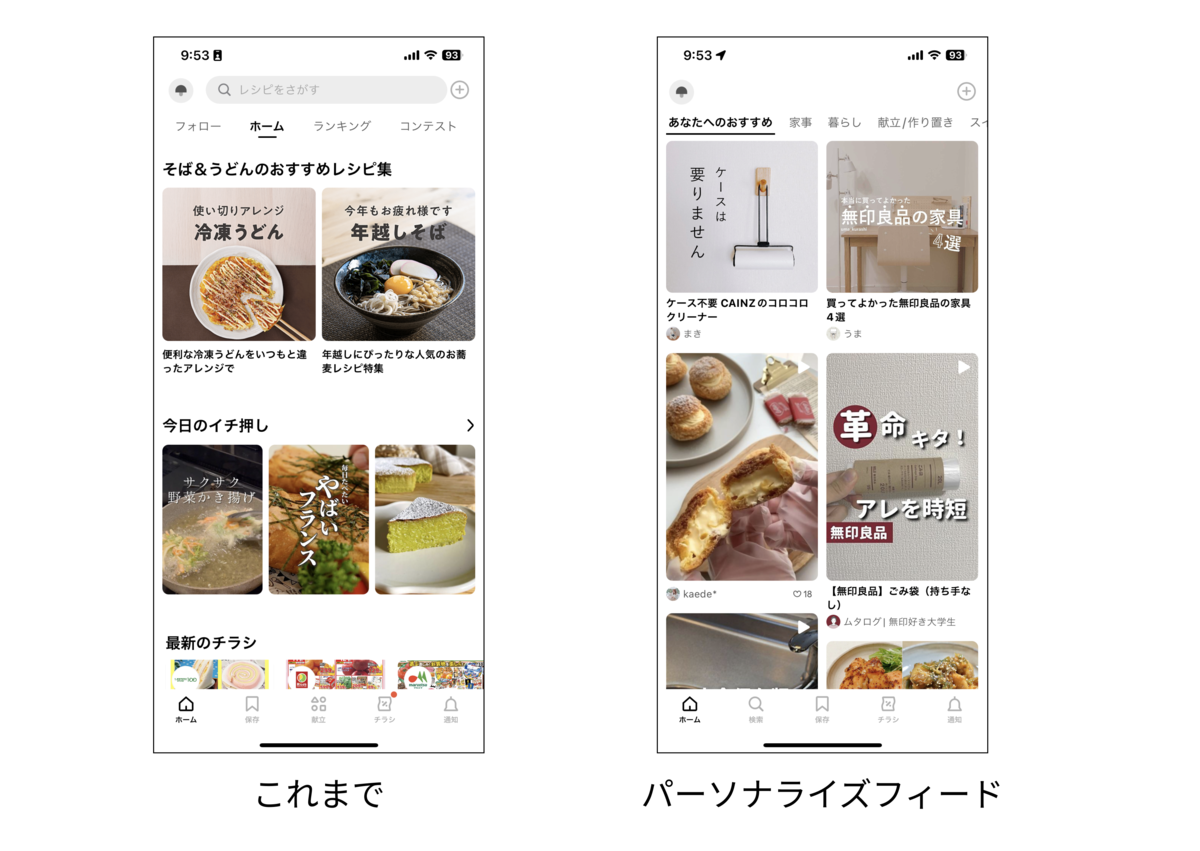
クラシルではこれまで複数のキュレーションされたコンテンツをまとめたリスト(画像左)を表示していましたが一部ユーザーに向けて単一のフィード(画像右)に変更しました。
アルゴリズムについて
コンテンツ閲覧履歴などの行動ログを分析してルールベースでレコメンドを行っています。 機械学習の導入を検討していますが導入にかかるコストや効果が不明確であることに加えてクラシルにおいてどのようにコンテンツをレコメンドしていくことがユーザーへの価値提供につながるのかを検証しているフェーズであるため現状はルールベースを採用しています。
クラシルのデータ基盤について
クラシルではDWHにSnowflakeを採用しておりユーザーの行動ログを管理しています。
ユーザーの行動ログは構築されたデータパイプラインを経由してニアリアルタイムに分析することが可能です。
また、dbtを採用しておりSnowflake上に取り込まれたデータをモデリングして各種KPIやレコメンド時に使用するデータを整備しています。
詳しくはこちらの記事で紹介しています。
クラシルでのSnowflakeデータパイプラインのお話&活用Tips
Reverse ETLとは?
アプリケーションなどから生成されたデータを抽出(Extract)・適切な形にデータを変換(Transform)・データ基盤にデータを格納(Load)する一連の処理をETLと呼びます。
Reverse ETLとはETLの逆でデータ基盤に格納されたデータを抽出・変換してアプリケーション側に格納する処理を指します。
アーキテクチャ
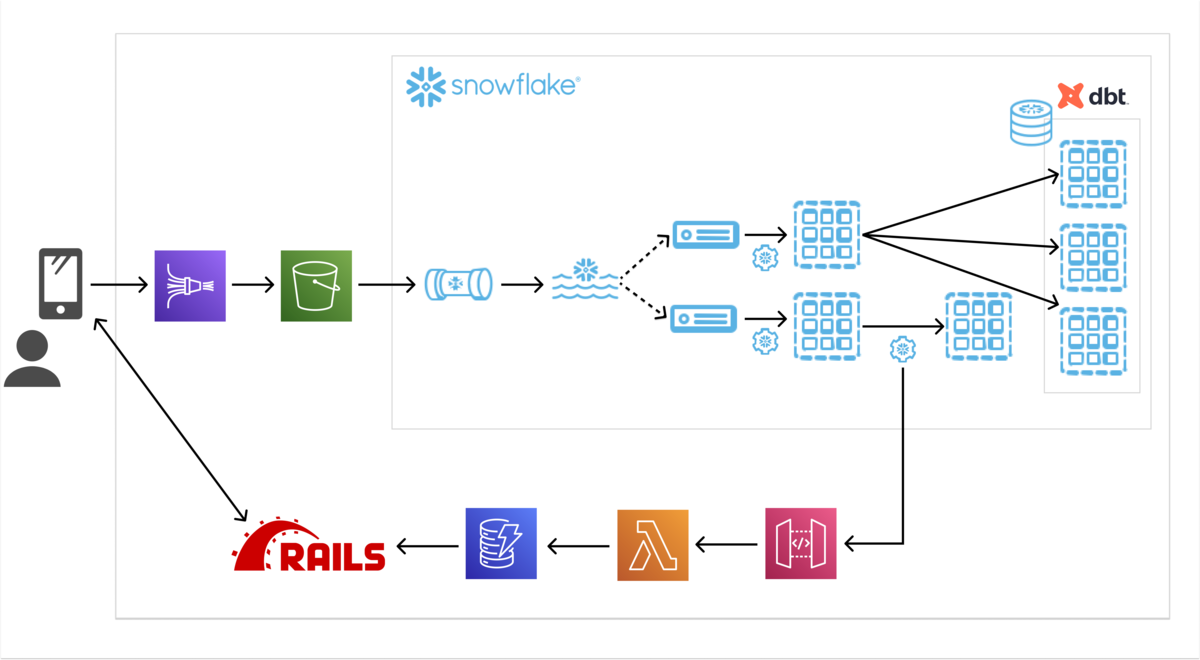
処理の流れ
大まかなレコメンドまでの処理は以下の通りです。
アプリ内の行動ログをKinesis Data Firehoseを経由してS3に配置
一定の時間・ログサイズになるとS3にログファイルが配置されます。 配置されるS3にはSnowflakeの外部ステージが設定されておりS3からSnowflakeにデータロードすることができます。S3からSnowflake側にログを格納
S3(外部ステージ)にログファイルが配置されたことをトリガーにSnowpipeを使用してマイクロバッチ的にログをSnowflake上にロードします。 これによりニアリアルタイムにログの分析をすることが可能です。レコメンドに必要なデータを作成・更新してレコメンドタスクを実行
Snowflakeにロードされたログからレコメンドに使用するためのデータ作成・更新・レコメンドをSnowflakeのタスク・サーバレスタスクを使い実行します。 タスク・サーバレスタスクにはDAGを設定することができるので処理に依存関係をもたせることでレコメンドに必要なデータの作成からレコメンドまでを一連の流れで実行することができます。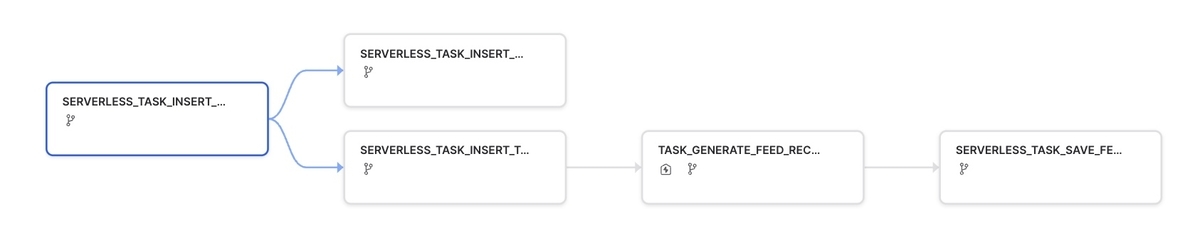
アプリケーションのDBへレコメンド結果をロード レコメンドタスクの後続タスクで外部関数を使用してアプリケーションが利用するDB(DynamoDB)へ結果を書き出します。 外部関数はSnowflakeから外部システムのコードを呼び出すことができる機能です。
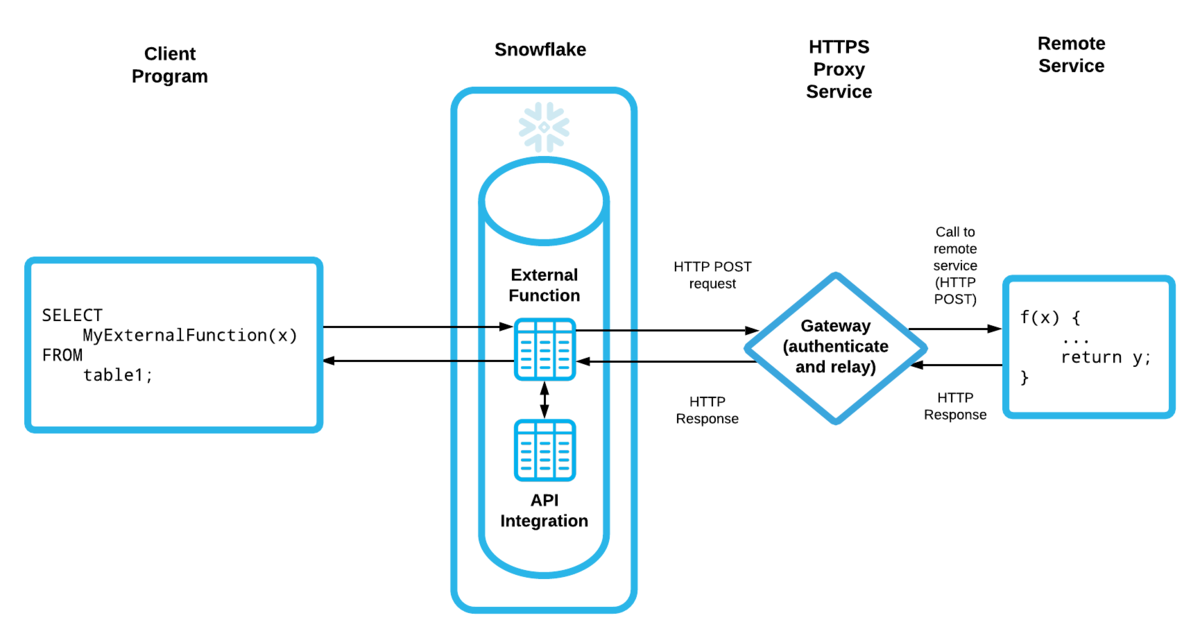
外部関数を使用することでログの格納からレコメンドをイベント駆動で実現できたことやサーバサイドからのレコメンド結果の取得が不要になりSnowflake上で処理を完結させることができます。 また、処理する件数が多い場合は効率的にさばけるようにSnowflake側で分割されて外部関数が実行されることで効率的にレコメンド結果を書き出すことできます。
課題と今後の展望
エラー・障害の監視強化
これまでデータ基盤はデータを分析するための基盤であったためユーザーに影響があることはありませんでした。
今回のパーソナライズフィードの取り組みによって状況は変化しユーザーに影響のあるデータ基盤に状況が変わりました。
それによりこれまで以上にエラー・障害検知やSLOの定義などの重要性が上がりました。
これまで大きな障害等なく運用できていますが改めてアラートの設定などを見直していく必要があると考えています。
チューニング
現在パーソナライズフィードは一部のユーザーに向けて展開しているため全展開となればデータ基盤に対するコスト・負荷やレコメンドの処理時間の増加などが見込まれるため現在の設計や今後の追加実装においても負荷に耐えうる設計になっているかを考えて実装する必要があると考えています。
さいごに
クラシルではデータエンジニア・MLエンジニア・データアナリストを募集しています!
今後は機械学習モデルの導入を進めてよりユーザーへの価値提供を加速させていきたいと思っていますので
ご興味のある方はぜひカジュアルにお声かけください!!
dely.jp