TRILL開発部の石田です。
WWDC 2021でShazamKitが発表され、楽曲認識アプリであるShazamのリソースを誰でも使えるようになりました。
今回はそのShazamKitの実装例と、Shazamで使われている楽曲認識のアルゴリズムであるAudio Fingerprintingについて紹介したいと思います。
ShazamKitについて
スマートフォンなどのマイクから音楽を取り込み、その音楽が何かを教えてくれるサービスの代表格としてShazamがあります。 ShazamKitは、Shazamが持っている膨大な音楽のカタログと、音楽を認識するアルゴリズムを使うことができるライブラリです。
カタログ自体を作成することもでき、デベロッパーが用意した音源を使って独自のカタログを作り、それに対して録音した音声を認識させることもできます。
ShazamKitの利用にはXcode13が必要で、iOS15以降の端末でしか動作しません。
ちなみにShazamKitはAndroidでも利用可能です。
ShazamKitの実装
ShazamKitを使って、iPhoneのマイクから音楽を取り込み、その音楽が何かを表示するアプリの実装していきます。
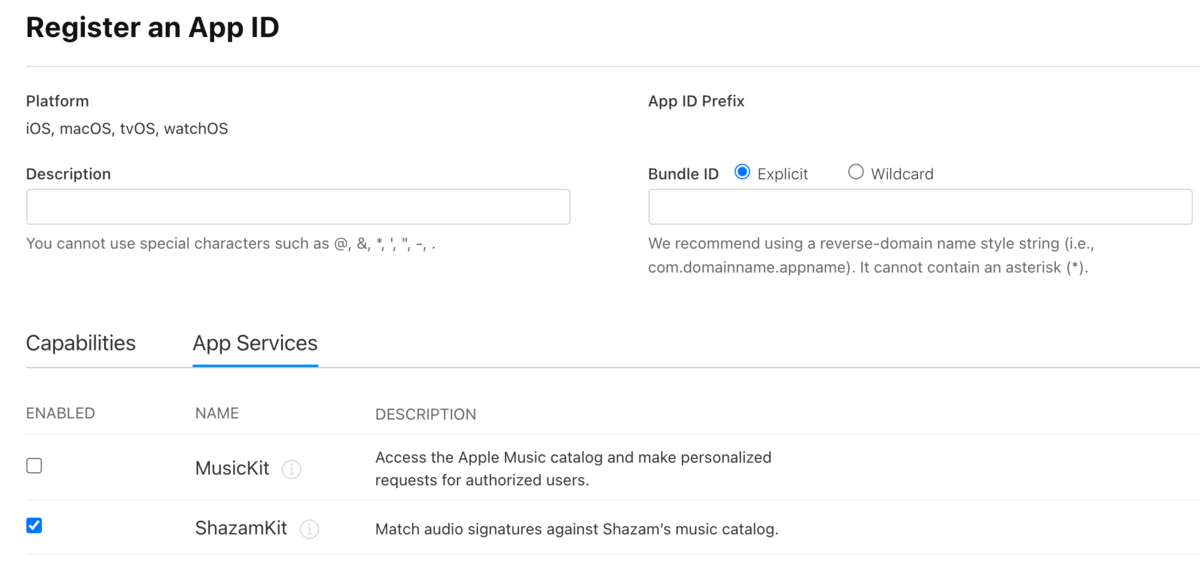
まず、iPhoneのマイク利用の許可を得るためInfo.plistのNSMicrophoneUsageDescriptionを入力します。 またApple Developerのコンソールから、対象アプリにShazamKitの利用を有効にする必要があります。
まず楽曲の入力ですが、AVAudioEngineで受け取った音声入力を、SHSessionに流していきます。
具体的には以下のようなコードになります。
let audioEngine = AVAudioEngine() let session = SHSession() audioEngine.inputNode.installTap(onBus: 0, bufferSize: 1024, format: nil) { (buffer, _) in session.matchStreamingBuffer(buffer, at: nil) } try? audioEngine.start()
これによって入力された音声が自動的にサーバに送られ、結果が返ってきます。
結果はデリゲートメソッドで受け取ります。 楽曲が見つかった場合と見つからなかった場合のメソッドが用意されています。
注意しなければいけないのが、これらデリゲートメソッドはバックグラウンドスレッドで実行されるため、UIに変更を加える場合はメインスレッドで処理する必要があります。
func session(_ session: SHSession, didFind match: SHMatch) { // 楽曲が見つかった場合に呼ばれる } func session(_ session: SHSession, didNotFindMatchFor signature: SHSignature, error: Error?) { // 楽曲が見つからなかった場合に呼ばれる }
上記を用いてSwiftUIで簡単なアプリを実装をしてみました。 コードは以下のようになります。
import SwiftUI struct ContentView: View { @StateObject private var viewModel = ContentViewModel() var body: some View { VStack(alignment: .center, spacing: 10) { Spacer() AsyncImage(url: viewModel.artworkURL) { image in image .resizable() .frame(width: 300, height: 300) .scaledToFill() .cornerRadius(10) } placeholder: { ProgressView() } Text(viewModel.title) .font(.title) .fontWeight(.bold) Text(viewModel.artist) .font(.title2) Spacer() Button(action: {viewModel.startFinding()}) { Text(viewModel.isFinding ? "Listening" : "Tap to Shazam") } .tint(.primary) .buttonStyle(.bordered) .controlSize(.large) Spacer() } } }
import AVFoundation import ShazamKit import SwiftUI class ContentViewModel: NSObject, ObservableObject { @Published private(set) var isFinding = false @Published private(set) var title = "" @Published private(set) var artist = "" @Published private(set) var artworkURL = URL(string: "") private let audioEngine = AVAudioEngine() private let session = SHSession() override init() { super.init() session.delegate = self AVAudioSession.sharedInstance().requestRecordPermission { _ in } } func startFinding() { guard !audioEngine.isRunning else { return } audioEngine.inputNode.installTap(onBus: 0, bufferSize: 1024, format: nil) { (buffer, _) in self.session.matchStreamingBuffer(buffer, at: nil) } try? audioEngine.start() isFinding = true } private func stopFinding() { audioEngine.inputNode.removeTap(onBus: 0) audioEngine.stop() DispatchQueue.main.async { self.isFinding = false } } } extension ContentViewModel: SHSessionDelegate { func session(_ session: SHSession, didFind match: SHMatch) { stopFinding() guard let items = match.mediaItems.first else { return } DispatchQueue.main.async { self.title = items.title ?? "" self.artist = items.artist ?? "" self.artworkURL = items.artworkURL } } func session(_ session: SHSession, didNotFindMatchFor signature: SHSignature, error: Error?) { stopFinding() DispatchQueue.main.async { self.title = "not found" } } }
これだけのコードで実際に楽曲を認識させることができます。
Audio Fingerprintingについて
Shazamの楽曲認識アルゴリズムであるAudio Fingerprintingについて解説します。 詳しい内容は論文 (An Industrial-Strength Audio Search Algorithm) にまとまっているので、詳細はそちらを参照していただければと思います。 また、説明に用いる画像のいくつかは論文より引用していますので、画像の詳細を確認したい場合も元の論文を参照していただければと思います。
Shazamはカフェなどで流れている音楽を認識し、それが何の楽曲かを検出してくれるアプリです。 そのため、人の声や周囲の雑音など、楽曲以外の音声が入力に入っていても正しく楽曲を検出するような頑健なアルゴリズムが必要です。
音声は空気中を伝搬する波なので、楽曲認識ではその波自体のマッチングを行えば良いように思います。 しかし、CDなどから取り込んだ電子的な音源ならまだしも、環境音などノイズが乗っている音声は容易に波の形が変わってしまうので、カフェなどでの楽曲認識には向きません。
そこで、Audio Fingerprintingではスペクトログラムという表現を使います。下記の画像はWikipediaの Spectrogramの記事 より引用しています。
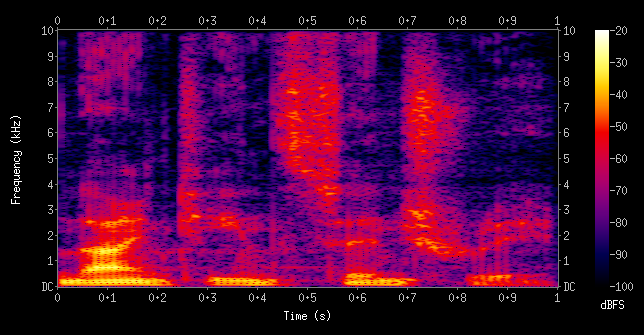
スペクトログラムは、横軸が時間、縦軸が周波数、色の濃淡で音の強さ (大きさ) を表現します。 例えばある曲をスペクトログラムに変換したとき、低い音がなっている場面ではスペクトログラムの下のほうが白くなり上のほうは黒くなり、逆に高い音がなっている場面では上が白で下が黒、というようになります。
楽曲をスペクトログラムに変換後、音の強さを用いてピークを検出します。
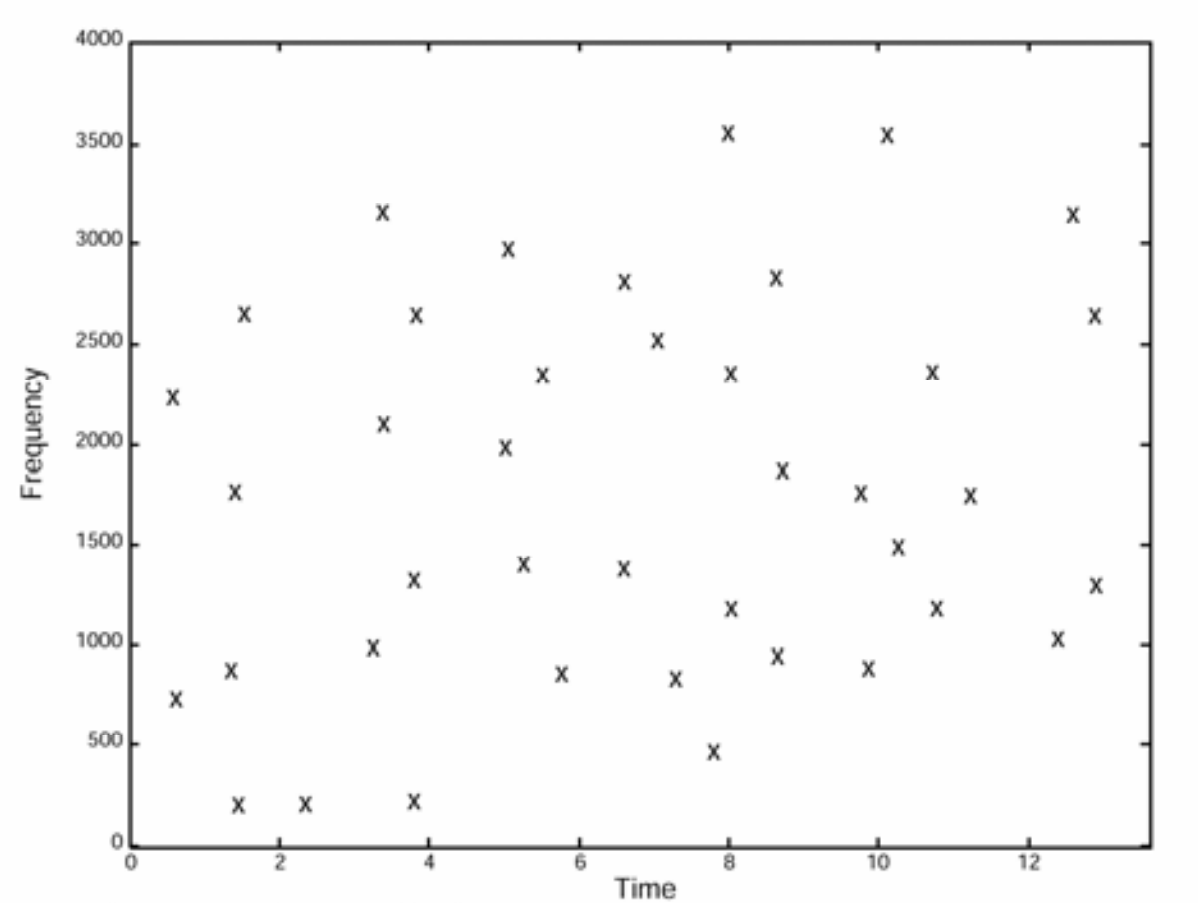
スペクトログラムでは時間、周波数、音の強さの3次元で表現されていたデータが、あるスレッショルドでピークを抽出することで時間と周波数の2次元の星座図のようなデータになりました。
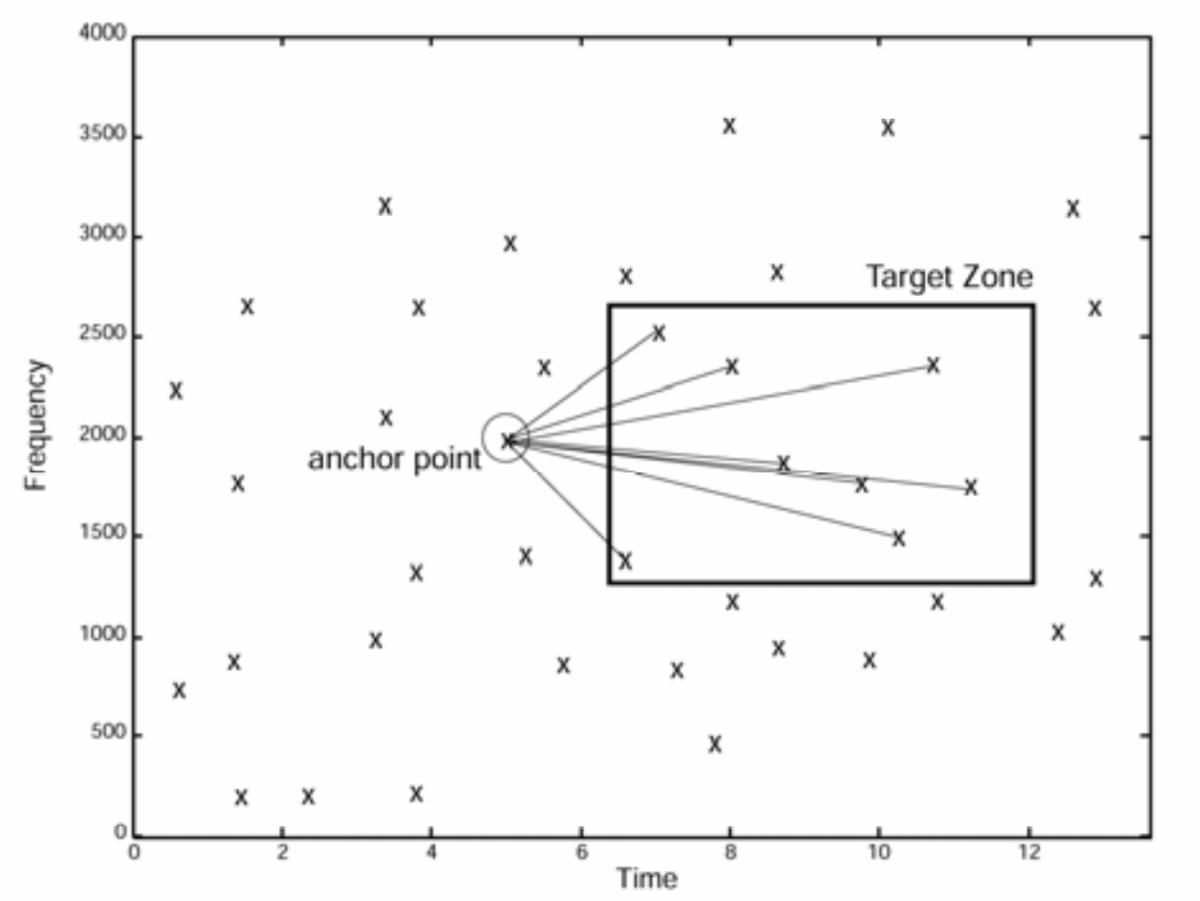
Audio Fingerprintingでは、この星座図から任意の2点を選択し、それを特徴量として用います。 2点の選択は下図のように無数に行うことが出来ます。
星座図のある点1は横軸:時間 ( ) と縦軸:周波数 (
) から
と表現することができます。
同様に点2は
と表現されます。
としたとき、点1と点2のペアを
] と表現することができます。
これがAudio Fingerprintingで用いる特徴量となります。
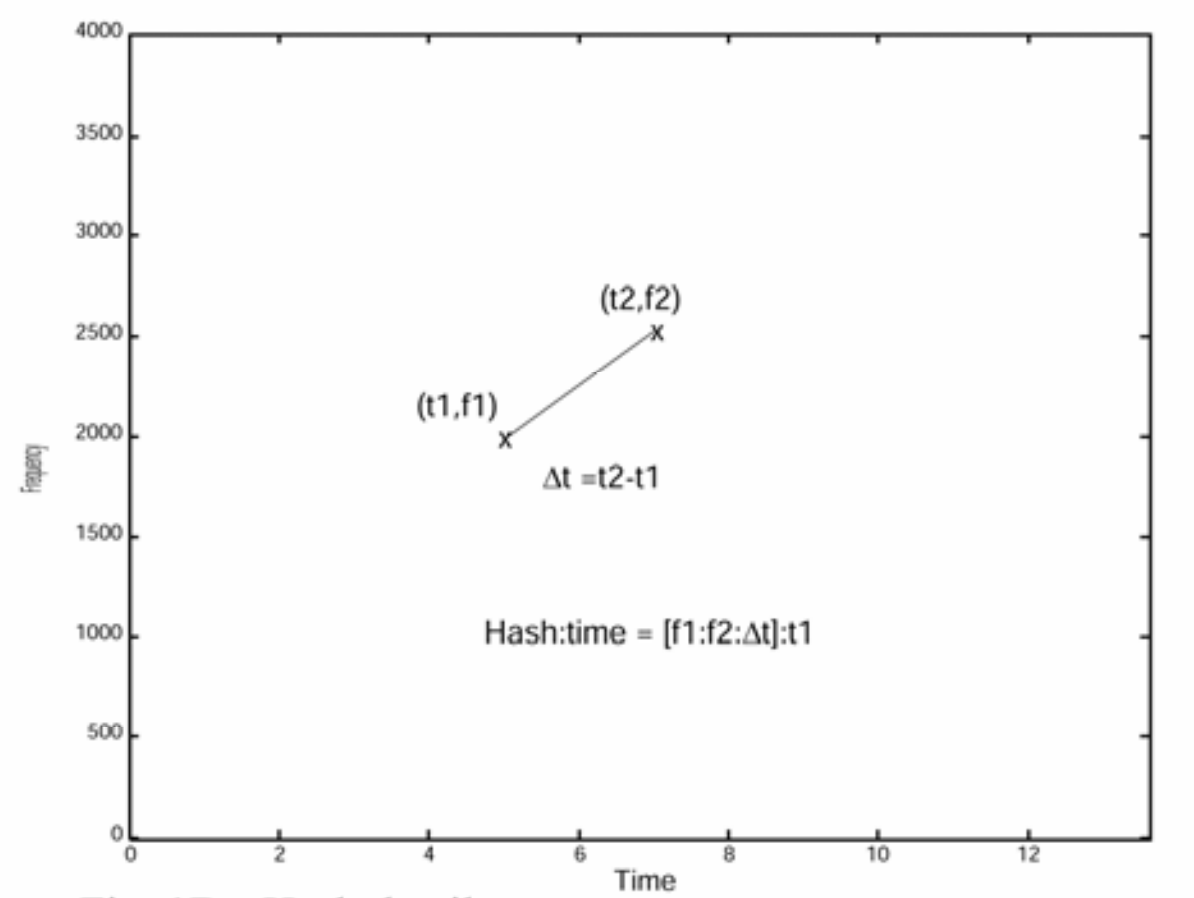
具体例を用いて説明すると、マイクで録音した10秒の楽曲があったとき、3秒の位置に1000Hzのピークが、4秒の位置に2000Hzのピークがあったとき、そのペアは [ 1000Hz : 2000Hz : 1秒 ] と表現できます。
何故 ] ではなく
] と表現しているかというと、カフェで流れている楽曲が元音源でいう何秒の位置のものか分からないため、ピークの位置関係 (
) のみを特徴量として使っています。
この特徴量を用いて楽曲のデータベースに対してマッチングを行っていきます。
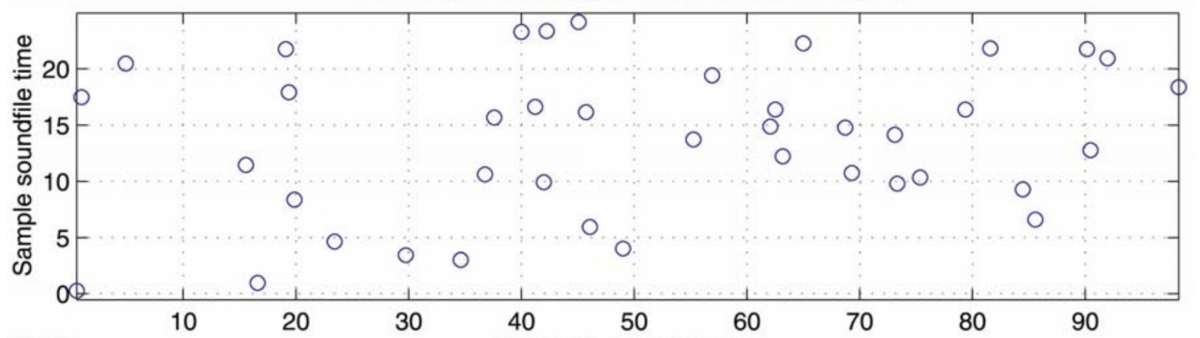
上図はマイクで録音した楽曲とデータベース内のとある楽曲とのマッチング例となります。
横軸はデータベースの楽曲の時間、縦軸はマイクで録音した楽曲の時間であり、図中の点は上記で抽出した特徴量がマッチした部分となります。
この図でいうと、例えば録音した楽曲 (縦軸) の17秒の位置とデータベースの楽曲 (横軸) の0秒の位置で、周波数とその位置関係を表す ] がマッチしたものがあったことになります。
この方法でマッチしたポイントが多い楽曲を正解と検出してもよいのですが、これだけでは精度がでません。 実際に正解の楽曲をマッチングさせた場合には下図のようになります。
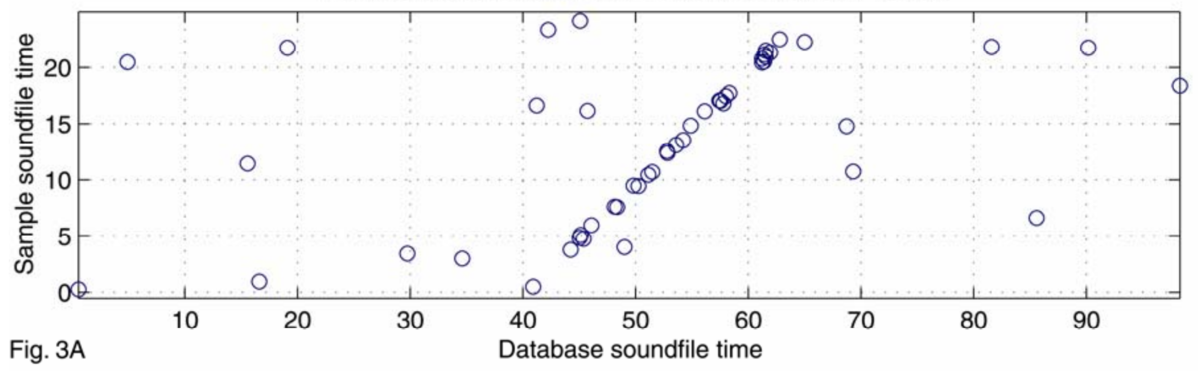
中央付近にマッチしたポイントが一直線に並んでいる部分があります。 これは録音した楽曲の開始点が正解楽曲の40秒付近であり、そこから同じ時間経過に対して高い確率でマッチするため、一直線にポイントが並ぶことになります。 単純なマッチングの数ではなく、このような一直線にマッチするという特徴を使って、Shazamでは楽曲を検出しています。
以上がShazamの楽曲認識アルゴリズムであるAudio Fingerprintingの解説です。 繰り返しになりますが、より詳しい解説は論文にまとまっているので、興味のある方は参照していただければと思います。
まとめ
WWDC2021で登場したShazamKitの実装例とAudio Fingerprintingの解説をしました。
何気なく利用しているShazamですが、背後にあるアルゴリズムを知ると、今後利用するときにスペクトログラムや一直線にマッチする結果を想像せずにはいられませんね。
delyではサービスをさらに大きくすべく、エンジニアを積極採用中です。 もし興味がありましたら、気軽にアクセスしていただければと思います。