
はじめに
はじめまして。 クラシル開発部でデータエンジニアをしておりますharry(@gappy50)です。
この記事は dely Advent Calendar 2021 および Snowflake Advent Calendar 2021の9日目の記事です。
昨日はうっくんさんからのNotionでJiraを作ろう!というとても興味津々話でした!! やっぱりNotionは色々できるのでいいですね◎
それと私のお話で恐縮ですが、昨日はSnowflakeのイベントSnowdayにてクラシルでのSnowflakeを活用したニアリアルタイム分析の事例についてお話をさせていただきました。
今回はSnowdayでお話した内容のデータエンジニア寄りな詳細と、どのようにSnowflake*1を活用しているかを紹介させていただきたいと思います!
最近のクラシルデータ基盤のお話
これまでのクラシルでのデータ基盤については以下の記事でも昨年ご紹介させていただきました!
これらのデータ基盤は今のクラシルにとっては最適化されたデータ基盤として成熟しており、最小限のリソースでも日々のサイクルが回せるようになっています。
ただし、最近のクラシルでは以下のニーズを叶えられるデータ基盤が必要になってきています。

それらを実現すべく2021年の8月からSnowflakeを導入し、リアルタイム分析やアプリケーション利用が可能なデータ基盤を構築すべくデータパイプラインを整備しています!
クラシルでのSnowflakeデータ基盤構成
ニアリアルタイムでのデータ分析を実現するために、まずは以下の構成でログデータを取り込むためのデータパイプラインを構築しました。
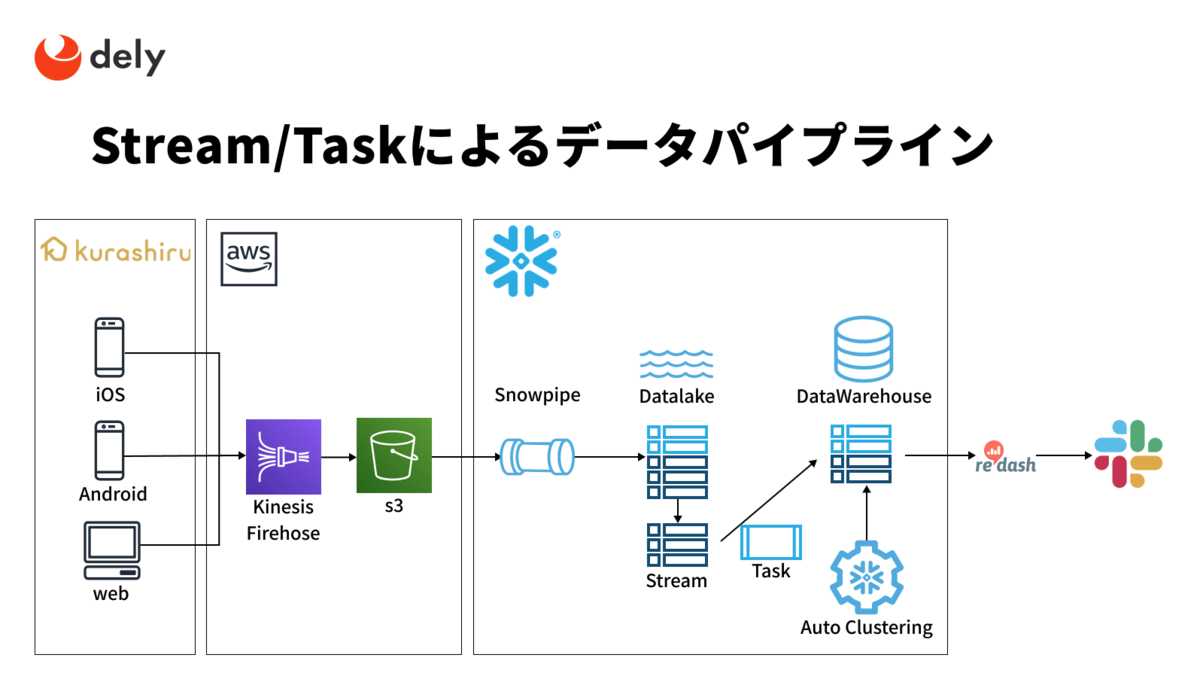
一連の流れは以下のようになってます。
- s3に吐かれるログデータをSnowpipeにて取り込み
- Data Lakeに対してStreamを設定
- マイクロバッチ的にTaskにてDWHへ加工処理を実施
Snowpipeはs3にログが配置されたのを検知して自動的にロード処理を実行してくれます。
ロード処理をしたデータはStreamで追加・削除・更新などの変更を追跡しており、新規で発生したデータのみを対象にして後続のテーブルへのデータ加工・格納をマイクロバッチで実行しています。
このプロセスはいわゆる変更データキャプチャ(CDC)といわれるプロセスで、Snowpipe+Stream+TaskでCDCを実現したデータパイプラインを構築しています。
こちらの詳細はSnowflakeのドキュメントにも記載されていますので、そちらをご覧ください!
これによりログが吐かれてから最短数分でログデータの分析が可能な状態になっています。
また、これまでの分析よりも高速なレスポンスを日々のチューニングなしで実現できました! (ここに至るまでの紆余曲折はSnowdayでもお話しているので是非ご視聴ください)
今やっていること
クラシルでは様々な方が分析目的でSQLを記述する文化や、Slackで分析結果を共有しあいながら意思決定をする文化が醸成されています! (入社時に一番驚いた点です!)
ただし、都度DWHから分析を行うためにクエリを記述していくと毎回同じようなクエリを書かなきゃいけなくなったり、同じような分析だけど指標の算出ロジックが異なったりと結構カオスになりがちです。
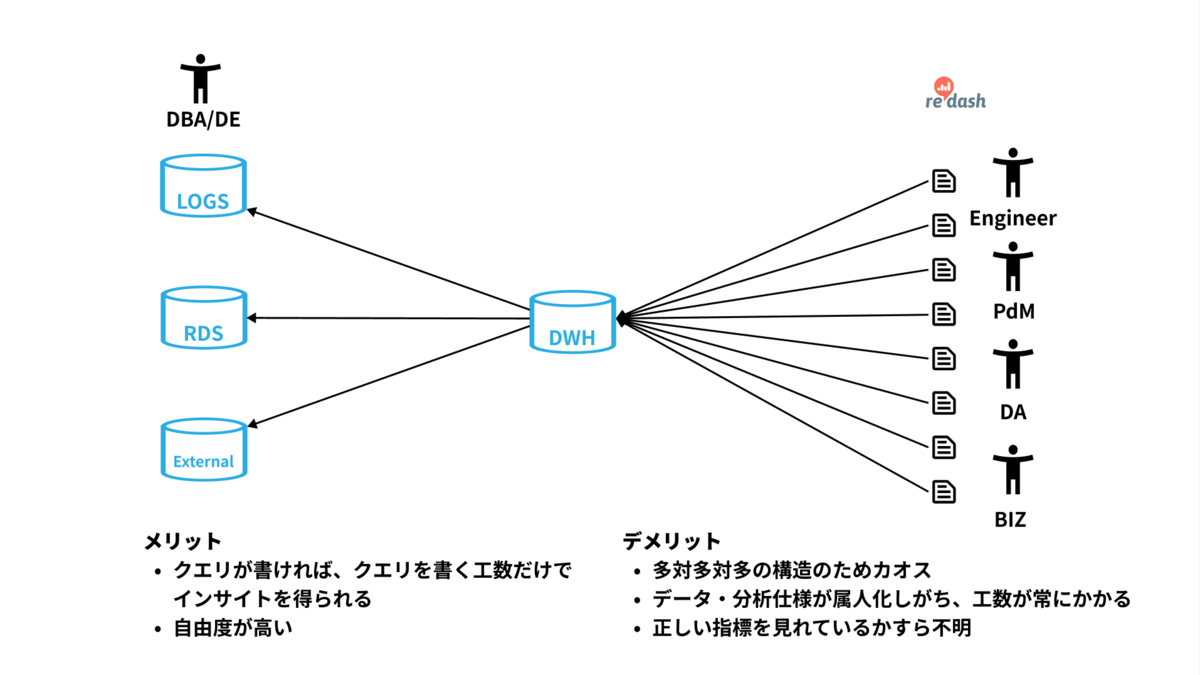
これらの現状から日々のモニタリングや分析の運用負担を削減しつつ、あわせてアプリケーションで利用ができるだけのデータ品質を保証できないかと考えました。
そのため、現在は中間ビューやデータマート相当のビューを作成し分析工数の削減と品質担保をするべくdbtを導入しはじめています。
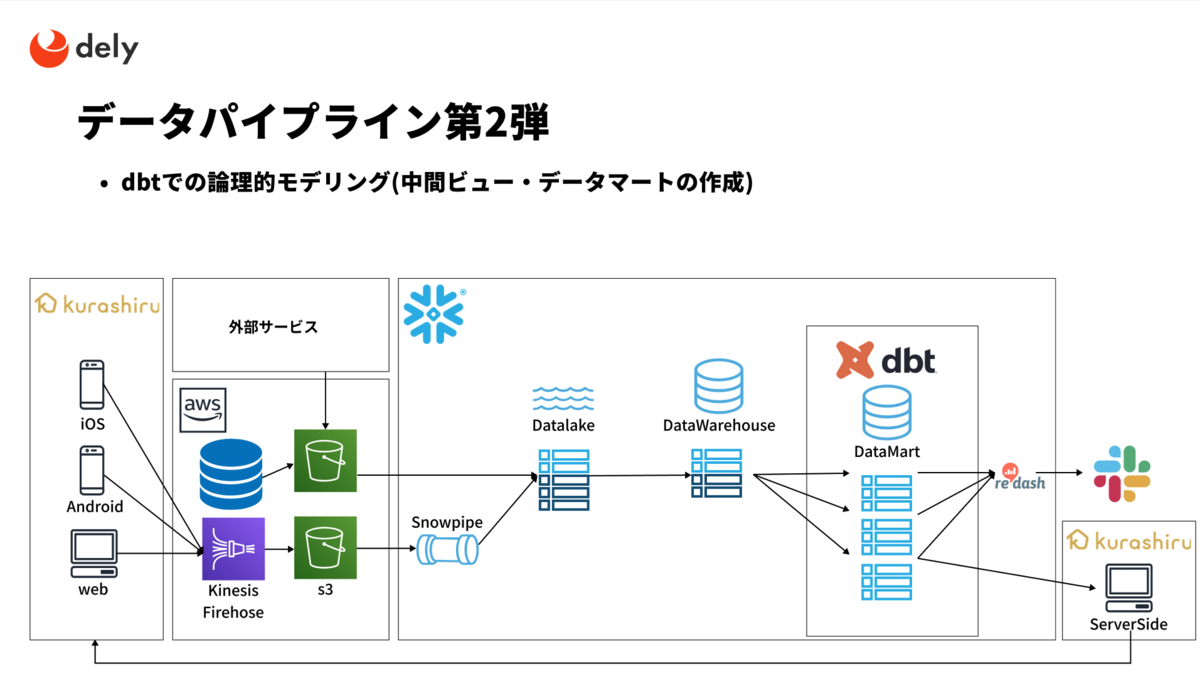
現時点では分析目的の利用にとどまっているので以下の方針で少しずつ活用をしていこうと考えています。
- Snowflakeのコンピューティングパワーを信頼した論理データウェアハウスアーキテクチャ
- 実テーブルを作らずにまずはビューを作ろう
- 論理的なモデリングであればリアルタイム性も引き続き担保できる
- 要件を明確にした上で実テーブル化しよう
- 学習途中、徐々に利用もスケールしていくのでデータマート(DM)などが乱立したときにも戻しが可能な構成(仮想DM)
- 実テーブル化するときのコンピューティングリソースのコストが必要なインサイトを得るのに見合うものか
- 実テーブルを作らずにまずはビューを作ろう
データ基盤のエンジニアリングリソースが少ない状態で活用を目指しているフェーズではこの考え方が理想ではないかと思っています。 将来的には、アプリケーションで利用するデータのモデリングなどを司る基盤としてSnowflake+dbtを活用していきたいと考えています!
活用Tips
RedashのアノテーションをQueryTagに設定
概論ばかりだとせっかく読んでいただいたのに残念な感じになってしまいそうなので、ちょっとしたTipsも落としておきます!
先程の仮想DMや中間ビューの利用が進むのはいいことですが、それらが乱立しても誰が何を利用しているかはわかりにくくなりますし、破壊的な変更が必要なときにどこに影響があるのかもわからなくなります。
それでは、本来目指していたカオスの解消にはなりません。
そこで、我々が利用しているRedashのアノテーション(Redashのクエリ情報やユーザー情報)をSnowflakeのquery_tagに仕込むことにしました。
query_tagにアノテーションがJSONの文字列で格納されているので、Snowflakeの ACCESS_HISTORY と QUERY_HISTORY を結合することでどのテーブル/カラムが、どのRedashユーザー/ダッシュボードのクエリで使われている実績があるかまで特定可能になりました!
SELECT DISTINCT try_parse_json(Q.QUERY_TAG):Username::string as redash_user ,try_parse_json(Q.QUERY_TAG):query_id::string as redash_query_id ,D.value:"objectName"::STRING AS DIRECT_OBJECT_NAME ,ColD.value:"columnName"::STRING AS DIRECT_COLUMN_READ_FROM FROM ACCOUNT_USAGE.ACCESS_HISTORY H JOIN SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY Q USING(QUERY_ID) ,LATERAL FLATTEN(H.DIRECT_OBJECTS_ACCESSED) D ,LATERAL FLATTEN(D.value, RECURSIVE=>TRUE) ColD WHERE H.QUERY_START_TIME >= dateadd(week, -1, current_timestamp) AND NOT (D.value:objectName::string LIKE ANY ('SNOWFLAKE.ACCOUNT_USAGE.ACCESS_HISTORY','%TABLE_ACCESS_LOGS%')) -- 確認したいテーブル名 AND DIRECT_OBJECT_NAME IN (<利用実態を知りたいテーブル名>) -- 該当テーブルののカラムをクエリで参照しているかどうか AND Direct_Column_Read_From in (<利用実態を知りたいカラム名>) AND len(Q.QUERY_TAG) > 0 ;
↓参考にした記事↓ galavan.com
例えばテーブルAのカラムAとカラムBに数値的な問題があった場合、どれだけ影響あるか知りたくなりますよね。
その場合は上記のようなクエリを実行するだけで、誰がどのRedashを使っているかを確認することができます。

この場合は主にAさんとコミュニケーション取らないとダメですね。
その他でもSnowflakeのquery_tagはいろいろな用途にも使えると思いますので、他にもTipsあるようでしたら是非教えて下さい!
最後に
いかがでしたでしょうか?
Snowflakeを導入してからこれまでとTipsをお話させていただきました。
改めてですがクラシルのログデータは1日で3億レコードほどあるため、かなりのデータ量になります。
それらのデータ量にも関わらずニアリアルタイムでのELTや分析性能の向上などの、思っている以上のパワーを発揮してくれているかなと思っています。
ほぼほぼエラーのリカバリー等もなく、日々運用周りのメトリクスを確認する程度の運用のみで済んでいるのは本当にすごいなと改めて思っていますし、パイプラインや分析ツールの開発や活用への活動等、本当に必要なことに集中できるのはいいものですね。
少ないリソースでも最大限のパフォーマンスと信頼性を発揮しながら大規模ログデータのデータパイプラインを構築できるのは、Snowflakeの恩恵を受けられているおかげかなと思っています。
クラシルのデータパイプライン構築は徐々に形になり始めてきており、今後はデータ基盤をより活用するフェーズになってくるかなと思っています。
Snowflakeやdbtを使い倒してクラシルのデータからユーザーへの価値提供に貢献してみたい!と思うデータエンジニアの方々に関わらず、delyではエンジニア、デザイナー、PdMを積極採用しています。ご応募お待ちしております!
*1:Snowflakeは2016年に提供開始、2020年にAWS東京リージョンでも提供開始されたクラウドサービス。BigQueryやRedshiftなどのようなDWHの機能を持ち合わせたCloud NativeなDWHといった感じです。