
これまでクラシルでデータエンジニアをしておりましたが、最近クラシルリワードという別プロダクトでデータエンジニアをしております。
クラシルリワードのデータ基盤は以下に詳細がありますので、ご興味あればどうぞ!
本記事のタイトルは私がTwitter改めXにポストした投稿から抜粋しました(恥
おい、誰も騒いでないから騒ぐけどExternal Network AccessっていうSnowflakeから外部へアクセスできる機能、データサイロ完全にぶっ壊せるぞ。
— harry (@gappy50) 2023年10月20日
Federated Queryとして他のPFのDWHだけじゃなく独自のデータもAPIとかから取ってSnowflakeでクエリぶん回せるんだぜ。https://t.co/qj18hEkMAh
今日は、クラシルリワードとクラシルのデータをSnowflakeのExternal Network Accessを使って越境させて分析できるようにしたよ〜というお話をします。
まずはその前に少し小話を。 どうやるかだけ気になる人は後半をご覧ください。
クラシルとクラシルリワードのデータ基盤とデータ基盤よもやま話
クラシルリワードではGoogle Analytics for Firebaseの行動ログを主に分析するためデータ基盤はBigQueryをベースに据えて日々の分析業務を行っています。 一方、これまでわたしがいたクラシルではAWS上に構築されたSnowflakeに行動ログや各種データを格納して分析をしております。
各プロダクトがアジリティをもって意思決定をしていくには、余計なことはせずに大事なデータがあるところ、重心があるところに軸(DWH)を置いていくのがまずは正攻法ですよね。
クラシルの場合は、AWS環境上にのみデータがあるのでSnowflakeを使うのは自然な流れですし、クラシルリワードの場合はGCPにデータの重心があるのでそこを軸に考えるのが自然です。
ただし、それぞれのデータの利活用がどんどん進んでいくとこんな声も聞こえてきます。
(´-`).。oO(クラシルの○○のデータとクラシルリワードの△△のデータを串刺しでみることで◎◎の結果を知りたい)
(´-`).。oO(クラシルとリワードのデータをうまく突合できないかね?)
そういった場合、データエンジニアがこれまで考えるべきことは
😤 < (必要なデータunloadしてどっちかに寄せておくか〜)とか
😤😤 < (Embulkを使って全部データかき集めるか〜)とか
😤😤😤 < (データサイロをぶっ壊すための天下一武道会を開催してデータ基盤を統一するぞ!)とか。
データエンジニアの腕がなるところですね。後半になるにつれて鼻息が聞こえてきます😤
全社のデータ基盤をAにしました!とかBに移行しました!とかいろんな事例も世の中にはわんさかあるし、 長期目線で考えたらデータサイロはないほうがよいに決まってます。
ちなみにですが、データサイロは以下のようなものを指します。
データサイロとは、互いに分離され、社内の他部門、他部署からアクセスできないデータストレージ/管理システムのことです。これは、互いに通信したり情報を共有したりすることができない個別のシステムやデータベースにデータが保存されている場合に発生します。データサイロは、非効率、ミス、遅延の原因となるだけでなく、企業がデータを活用して有益な情報を取得し、より適切な意思決定をするうえで妨げとなります。その結果、社内の複数の部署や事業部門でデータが重複したり、一貫性なく使用されることが多くなります。
まさに今クラシルとクラシルリワードはデータサイロが起きそうな(起きてる)状況ですね。 我々の場合は、それぞれのデータの重心がAWSとGCPに分かれてしまっていることがより難しくしている原因ですね。
ただし、鼻息荒くするだけでこのデータサイロをぶっ壊すことはできません。 これらを解消するための価値やコストを説明できる状況にならなければそんなものは夢物語になってしまいます。 そもそも本当に組織のアジリティを落としてまでやるべきことなのかみたいなことまで考え出すとそんなに気軽に意思決定なんてできません。
特にAWSやGCPなどのプラットフォームを横断せざるを得ない場合、そのデータ量が多いものを重心がないほうへ寄せるのはストレージコストだけでなく、転送コスト、それらを実現するためのコンピューティングリソースのコストなどの運用コストを寄せ始めてからずっと払い続けることを意味しています。 そしてそれらを乗り越えてデータサイロをぶっ壊した!となっても、事業インパクトもなく、むしろ利便性を下げてしまったら本末転倒ですよね。
なので、各事業の状況や会社としての状況、それらに紐づく制約や条件によっては、データサイロをぶっ壊すとことがいいかといえばそうでないことも大いにありますし、逆にいえば最初から長期目線でデータサイロを起こさない意思決定をすることで利活用が進むことでかかってしまう莫大な移行コストを抑えるようなことも考えられると思います。 後者ができれば一番幸せではありますが、前者も後者もやり直しがほぼできない一発勝負の世界だということも肝に銘じないといけません。
そうやって、データエンジニアは鼻息ではなく溜息をつきながら都度都度必要なデータの出し入れするコストを払い続けるのです。
このような状況において、データサイロはぶっ壊すことは不可能なのでしょうか?
…もしかしたら、SnowflakeのExternal Network Accessがあればぶっ壊すことができるかもしれません。
External Network Accessのサンプルは以下に詳細があります。 この例ではSnowflakeのSQLからGoogle Translateを呼び出すサンプルを例示しています。
話長くなりました。本編です。
External Network AccessでBigQueryのデータをSnowflakeから呼び出す
元ネタはこれです。 medium.com
上記簡単に説明すると
- SnowflakeでExternal Network AccessというPuPrの機能を使うことで外部APIへセキュアにアクセスできる
- BigQueryやGoogle スプレッドシート等にあるデータセットもAPIから呼べるのでデータサイロ打破できる
- ただし、大量なデータを頻度高く取るとBigQueryからの転送コストやBigQueryとSnowflakeのどちらにもコンピューティングリソースのコストを払わないといけないから注意してね
みたいな記事です。
ただし上記記事のままだと、大量のデータを取得できてもSnowflake側で展開する際のコストがかかりすぎたり、そもそもデータをSnowflake上に展開できないことがあります。
そのため、UDTFsに変更をした上でSnowflakeからBigQueryのデータを取得してみたいと思います。 また、OAuthではなくGoogle Cloudのサービスアカウントを利用してアクセスしてみます。
今回は ACCOUNTADMIN で実装をしておりますが、External Network Accessは外部へのデータ出し入れが可能になる機能であるため、Snowflake上での適切な権限設定が必要であることは理解していただければと思います。
また、現時点(2023-10-25時点)ではPuPrの機能であることを念頭においておく必要があります。
まずBigQueryへのアクセスのためのルールをスキーマ内に作成します。
use hoge_dev.external; create or replace network rule bq_rule mode = egress type = host_port value_list = ('oauth2.googleapis.com','bigquery.googleapis.com');
次にサービスアカウントのアカウントキーを GENERIC_STRING としてシークレットを作成します。
create or replace secret bq_service_account type = GENERIC_STRING SECRET_STRING = '{ここに払い出されたアカウントキーの情報を入れる。必要に応じてエスケープしたりする。}';
そして、上記のネットワークルールとシークレットを使ってexternal access integrationを作成します
create or replace external access integration bq_access allowed_network_rules = (bq_rule) allowed_authentication_secrets = (bq_service_account) enabled = true;
最後に上記のexternal access integrationを使ってUDTFsを作成します。
CREATE OR REPLACE FUNCTION run_bq_query_table(projid string, sql string) RETURNS table(value variant) LANGUAGE PYTHON RUNTIME_VERSION = 3.8 HANDLER = 'BigQueryDataFetcher' EXTERNAL_ACCESS_INTEGRATIONS = (bq_access) PACKAGES = ('snowflake-snowpark-python','requests', 'google-auth') SECRETS = ('cred' = bq_service_account) AS $$ import _snowflake import requests import json from google.oauth2 import service_account from google.auth.transport.requests import Request class BigQueryDataFetcher: def __init__(self): self.headers = self._get_headers() @staticmethod def _get_headers(): # Snowflakeで作成したsecretから認証情報を取得 credentials_info = _snowflake.get_generic_secret_string("cred") credentials_dict = json.loads(credentials_info) credentials = service_account.Credentials.from_service_account_info( credentials_dict, scopes=["https://www.googleapis.com/auth/bigquery", "https://www.googleapis.com/auth/cloud-platform"] ) # 認証情報をもとにGCPのサービスアカウントのトークンを取得 credentials.refresh(Request()) # ヘッダー情報を返却 return { "Authorization": f"Bearer {credentials.token}", "Content-Type": "application/json" } def process(self, project_id, sql_query): # BigQueryにクエリを投げるエンドポイント query_url = f"https://bigquery.googleapis.com/bigquery/v2/projects/{project_id}/queries" # クエリを実行して初回のレスポンスデータを取得 response_data = self._execute_query(query_url, sql_query) job_id = response_data["jobReference"]["jobId"] location = response_data["jobReference"]["location"] schema = response_data['schema']['fields'] columns = [field['name'] for field in schema] # 取得した行データを{"カラム名": "値"}のjson formatに変換しtupleを返却 # UDTFではreturnよりもyieldにするほうが遅延評価の恩恵を受けて効率がよい # https://docs.snowflake.com/ja/developer-guide/udf/python/udf-python-tabular-functions#implementing-a-handler for row in response_data.get('rows', []): yield ({col: item['v'] for col, item in zip(columns, row['f'])}, ) # ページトークンが存在する場合は次ページのデータを取得する page_token = response_data.get("pageToken") result_url = f"{query_url}/{job_id}" while page_token: payload = { "timeoutMs": 180000, "location": location, "pageToken": page_token } response_data = self._get_query_results(result_url, payload) page_token = response_data.get("pageToken") for row in response_data.get('rows', []): yield ({col: item['v'] for col, item in zip(columns, row['f'])}, ) def _execute_query(self, url, sql_query): # BigQueryにクエリをpostする payload = { "query": sql_query, "useLegacySql": False, "timeoutMs": 180000 } response = requests.post(url, headers=self.headers, data=json.dumps(payload)) response.raise_for_status() return response.json() def _get_query_results(self, url, payload): # クエリの結果をgetする response = requests.get(url, headers=self.headers, params=payload) response.raise_for_status() return response.json() $$;
あとは、SnowflakeからBigQueryに投げるクエリとSnowflake側での変換処理を書いておしまいです。
select value:event_date::string as event_date, value:event_name::string as event_name, value:record_count::number as record_count, value from table(run_bq_query_table( '<GCPのProject ID>', 'select event_date, event_name, count(*) record_count from `events_*` where _TABLE_SUFFIX = ''20231001'' group by 1, 2' ));
どやぁ
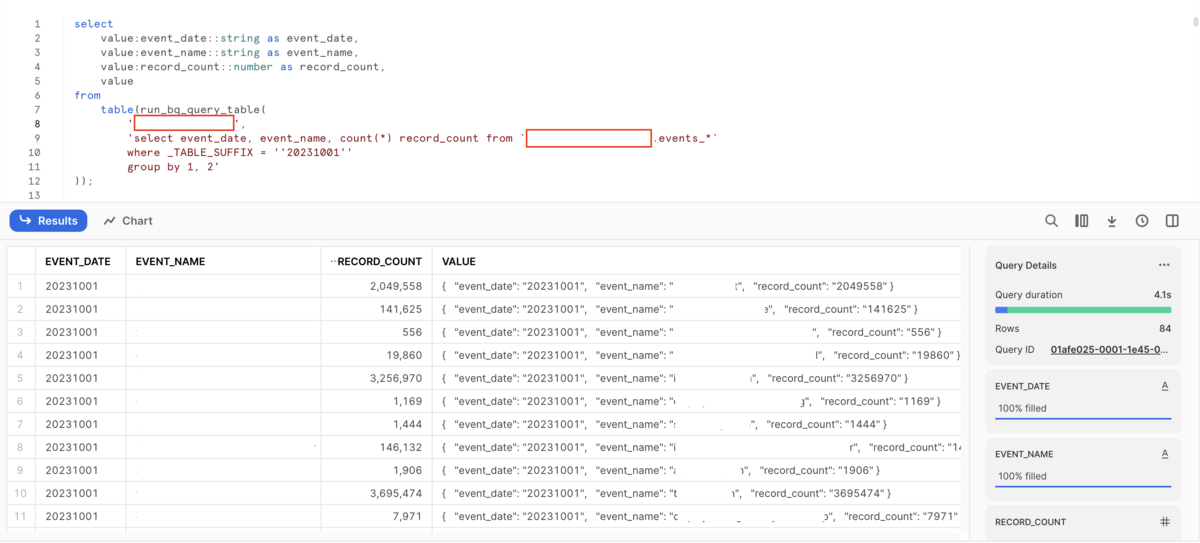
ある程度Snowflakeで扱いやすいようにBigQueryからのレスポンスを整形してvalueというvariantの1列にデータを格納するようにしています。 また、レスポンスが大きいとAPI側でページングがされるので、そこらへんもよしなに取れるようにしてます。 手元では100万行超、2列のデータをBigQueryから取得して表示されるまでXSで動かして1分程度で返ってきました。
ただし、VARIANT列にすべてのレコード情報をkey-valueの形で格納しているので、1行あたりのデータ量が最大長の16 MBを超えると何かしらの問題があるかもしれません。 また、BigQueryのSTRUCT型のレスポンスが結構カオスなので事前にBigQuery側でunnestする等の処理はしておいたほうが幸せになれそうです。 他にも、こうしたほうがもっとよいよ〜みたいなのあればぜひ教えてください💪
さいごに
いかがでしたでしょうか?
煩雑なデータエンジニアリングを日々行ったり、データサイロの解消のための天下一武道会を開催をせずに、SnowflakeからExternal Network Accessを使えば最速でデータサイロを解消することもできそうですね。
今回はBigQueryからのデータ取得をサンプルとして例示しましたが、流行りのOpenAIをSnowflakeにちょちょっと記述するだけでSQLから呼び出すこともできそうですし、他にも既存の外部データの連携やデータパイプラインに対しても色々な選択肢を取れるようになるので、色々と夢が広がりますね。
そういうわけで、External Network Accessはデータサイロをぶっ壊せる可能性がありますよというお話でした。