TRILL開発部のiOSエンジニアの石田です。
今年もdelyではアドベントカレンダーを行っており、本記事はその2日目の記事となっています。
昨日の1日目の記事は奥原さん (@okutaku0507) の「プロダクトマネージャー3年目の教科書」という記事でした。delyのエースPdMである奥原さんによる大作となっていますので是非ご覧ください。
本記事では、機械学習を使ってUIを補完するAppleの研究について紹介します。
AppleはMachine Learning Researchで機械学習に関する様々な研究を発表しています。 その多くはコンピュータビジョンや音声・テキスト認識のような研究なのですが、機械学習xUIという研究も行っております。
本記事ではその中でも、アプリのスクリーンショット(画像)から機械学習を使ってUIコンポーネントを認識し、アクセシビリティ機能を補完するMaking Mobile Applications Accessible with Machine Learningという研究を紹介したいと思います。
ちなみにこちらはCHI 2021という国際会議で発表されたScreen Recognition: Creating Accessibility Metadata for Mobile Applications from Pixelsという論文を元にしており、CHI 2021ではBestPaperにも選ばれています。 論文自体はこちらからアクセスできます。また、サマリーが動画としても公開されているので、ざっくり研究の概要を知りたい方はご参照ください。
背景
iOSには様々なアクセシビリティ機能があります。 その中でも、画面を音声で読み上げる視覚サポート機能であるVoiceOverは初期のiOSから備わっています。 以前の職場で、目の不自由な先輩が音だけ (VoiceOver機能) でiPhoneを使いこなしているのが記憶に残っています。
しかし、そのVoiceOverにも限界があります。
開発者が isAccessibilityElement などの設定を適切に行わなければ十分な形でVoiceOverを利用できません。
また、iOSアプリをネイティブで開発している場合は良いのですが、Unityのようなクロスプラットフォームフレームワークでアプリを開発すると、VoiceOverはほぼ使えない状態になります。
しかし当たり前なのですが、アプリを使っているユーザは視覚的にボタンやテキストを認識し、適切にUIを操作しています。 人間と同様に、機械学習を使って視覚的に (アプリのスクリーンショットのような画像から) UIコンポーネントを認識しVoiceOverとしてアウトプットすれば、アクセシビリティのメタデータが存在しなくても視覚に障害のある方がUIを適切に操作できるようになるのでは、というのがこの研究のモチベーションとなっています。
手法の概要
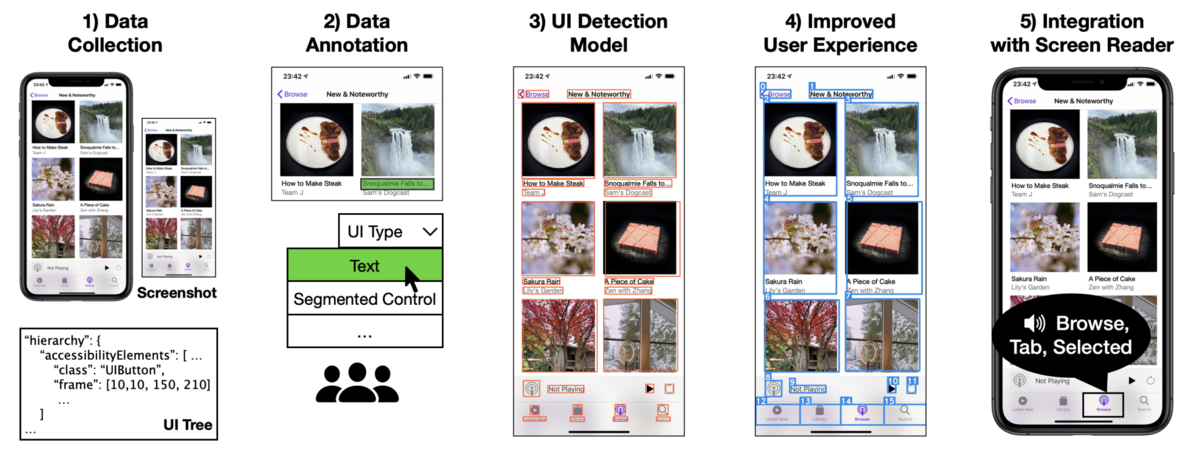
この研究は、入力がアプリのスクリーンショットのような画像であり、出力はVoiceOverのような画面の読み上げとなります。全体の流れは下図のようになります。
 (論文より画像引用)
(論文より画像引用)
- アプリのスクリーンショットやUI Treeのデータを集める
- スクリーンにメタデータを付与する (40人の作業者が実施)
- 機械学習を使って、画像からUIの検出をデバイス上で行う
- 画面読み上げの精度向上のために、UIの順序の認識やグルーピングを行う
- 生成されたアクセシビリティのメタデータから画面読み上げを行う
本研究のキモは以下の2点です。
- iPhoneのVoiceOverで使えるほどUIの検出スピードが早く、処理が軽量であること
- UIの状態やUIグループの認識などによってVoiceOverのUXをさらに向上させていること
これらについて詳しく解説していきます。
UIの検出と評価
スクリーンショットからUIを検出する問題設定はコンピュータビジョンの物体検出と同じです。そこで本研究ではまずFaster R-CNNのような物体検出で評価の高いモデルを採用しました。 しかし検証したところ、Faster R-CNNでは検出に1秒以上かかり、また120MBのメモリを使用するため、iPhone上で動作させるには適していませんでした。
そこでSSD (Single Shot MultiBox Detector) を使うことで、高速化と使用メモリの削減を行いました。 また、UIは他の物体検出のターゲットに比べ小さいため、FPN (Feature Pyramid Network) を用いることで、その問題を解決しました。 最終的に、計算速度は10ms、メモリ使用量は20MBを実現しています。
ここで簡単にR-CNNとSSDのアルゴリズムについて紹介します。
物体検出は、画像から対象のオブジェクトの位置・大きさ (矩形) とそれが何か (犬か車かなど) を認識する問題です。 そのため、画像認識とは違い、対象オブジェクトの領域も推定する必要があります。
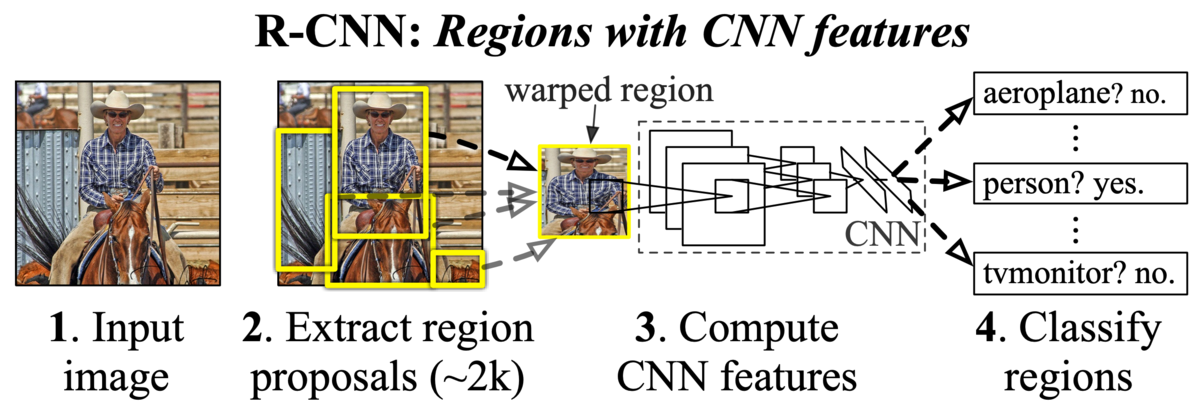
R-CNNは2つのステージに分かれていて、まずSelective Searchなどを使って領域提案を行い (オブジェクトと思われる領域を最大で2000検出) 、次にその抽出された領域画像に対してCNN (Convolutional Neural Networks) を使ってそれが何かを推定します (下図参照) 。このように領域の検出と物体の検出の2つの問題を問いていることが処理の遅さの原因でした。
 (論文より画像引用)
(論文より画像引用)
それに対してSSDでは、Single Shotという名前の通り、ステージを2つに分けることなく1ステージで領域検出から物体認識まで行います。
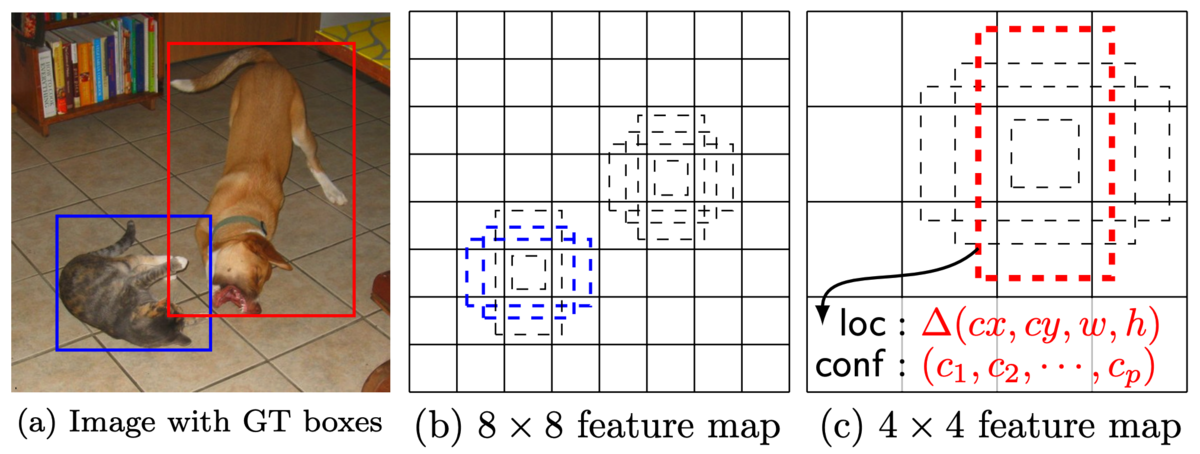
まず様々なスケールの特徴マップ (4x4や8x8) を用いて画像を表現し、それぞれの各要素に対して異なるアスペクト比のデフォルトボックスという矩形を用意します。 そして各デフォルトボックスについてクラス分類を行い、スコアを出します。 スコアの高いデフォルトボックスの重なりを使って、領域を検出します。
 (論文より画像引用)
(論文より画像引用)
このアルゴリズムを用いて実験を行いました。実験では、色んなカテゴリーのアプリから得た5,002のスクリーンショットを用いています。
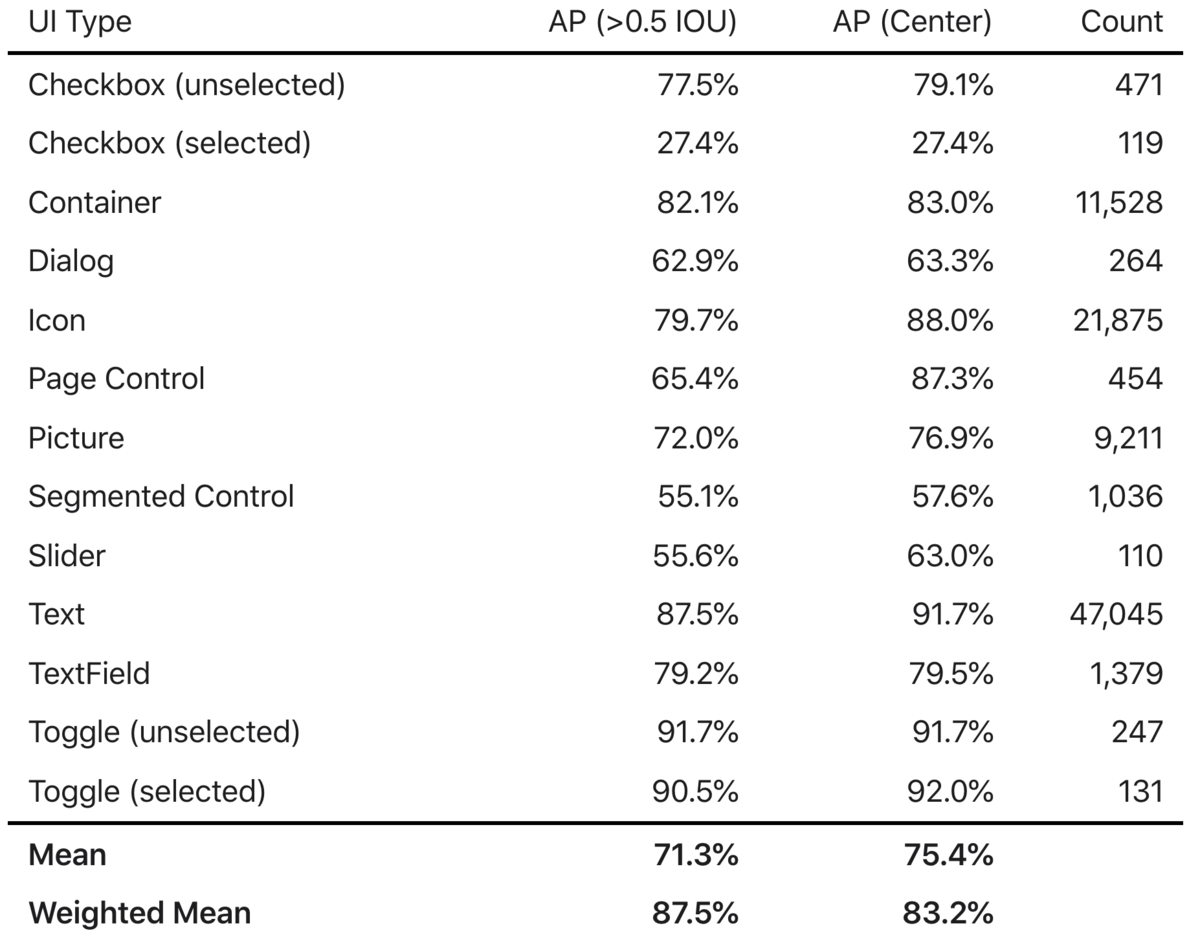
各UIエレメントの検出結果は以下のようになります。APはAverage Precisionの略で、物体検出では適合率と再現率がトレードオフなのですが、それをよしなに評価する指標です。 適合率と再現率は、例えばCheckboxと検出したものが実際にCheckboxだった割合が適合率で、存在するCheckboxのうちCheckboxと検出できた割合が再現率となります。 また、物体検出では物体が矩形で検出されるのですが、その矩形が正解とどれくらいオーバーラップしているかがIOUとして表現されます。
 (論文より画像引用)
(論文より画像引用)
IOUが0.5より大きい場合の平均APは71.3%となります。 これに、UIタイプの出現頻度を重み付けすると82.7%となりました。 アプリのUIは同じ出現頻度ではなく、テキストやアイコンは頻度が高く、逆にチェックボックスやスライダー、トグルは出現頻度が低いのですが、こういった出現頻度を重み付けしています。
結果を見ると、チェックボックスは精度が低く、これは出現頻度の低さに起因するものと考えられます。 しかし、同様に出現頻度が低いトグルは高い精度で検出できています。 深ぼってみると、チェックボックスはアイコンと誤認識される場合が多く、このような低い精度となっているようです。
UI検出の問題点とその改善
前項で、UIを検出する手法と評価を紹介しました。 しかしUIには、選択状態か否か、ボタンなのかタブなのか、タップ可能なアイコンか否か、などのメタデータが含まれます。 理想のアクセシビリティ機能を提供するためには、これらのメタデータをユーザに提供する必要があります。
このような問題を、本研究ではヒューリスティックな方法で解決しています。
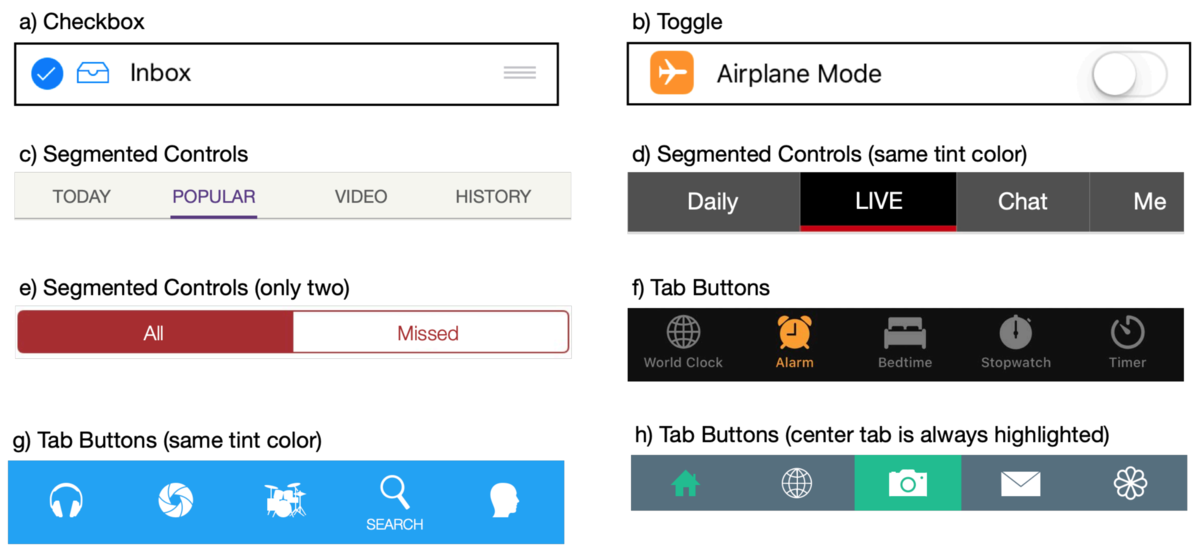 (論文より画像引用)
(論文より画像引用)
例えば上図のようなタブやSegmented Controlsでは、それぞれの色の出現頻度などからtint colorを類推できます。 そのようにして、タブでは90.5%の精度で、Segmented Controlsでは73.6%の精度で選択状態を認識することができました。
また、タップ可能か分からないアイコンなどもありますが、それに対してはGBDT (Gradient Boosting Decision Tree) を使って判別し、90.0%の適合率を維持したまま73.6%の再現率を達成しました。
さらに、VoiceOverのためにはUIのエレメントを認識するだけではなく、UIをグルーピングしたり順序付けする必要があります。 グルーピングがないとUIエレメントを読み上げるだけなので (例えばタブはアイコンとテキストに分解される) 、ユーザはUIを適切に認識するのに多くの時間がかかってしまいます。
下図はUIをエレメントで検出したものと、グルーピング・順序付けをした比較になります。 タブやUITableViewのCellが適切にグルーピングされているのが分かります。
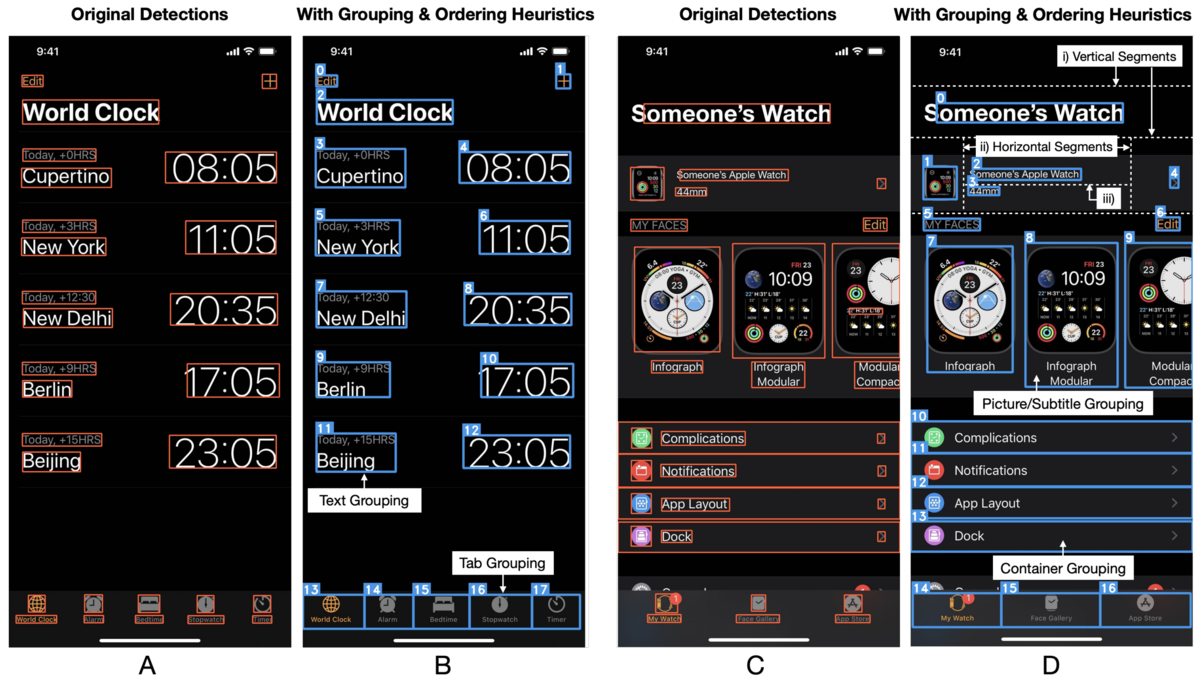 (論文より画像引用)
(論文より画像引用)
これらは、UIのタイプや距離、サイズを用いて検出しています。 例えばタブであれば画面の下部にあることや、テキストのグループであれば位置関係 (xが同じとかcenterが同じとか) を使っており、機械学習に任せるというよりはヒューリスティックな方法で検出しています。
このようにして単純なUIの検出を超えて、アクセシビリティがより良いUXとなるよう改善を行いました。
実際のユーザによる評価
前項の検出の改善を含めて、VoiceOverを実際に数年以上使っているユーザを対象に、本研究の評価を行いました。 評価に用いたアプリはApp Storeで入手可能なもので、VoiceOverが適切に機能しないものを選びました。
使いやすさを5段階で評価してもらった結果は下図のようになりました。
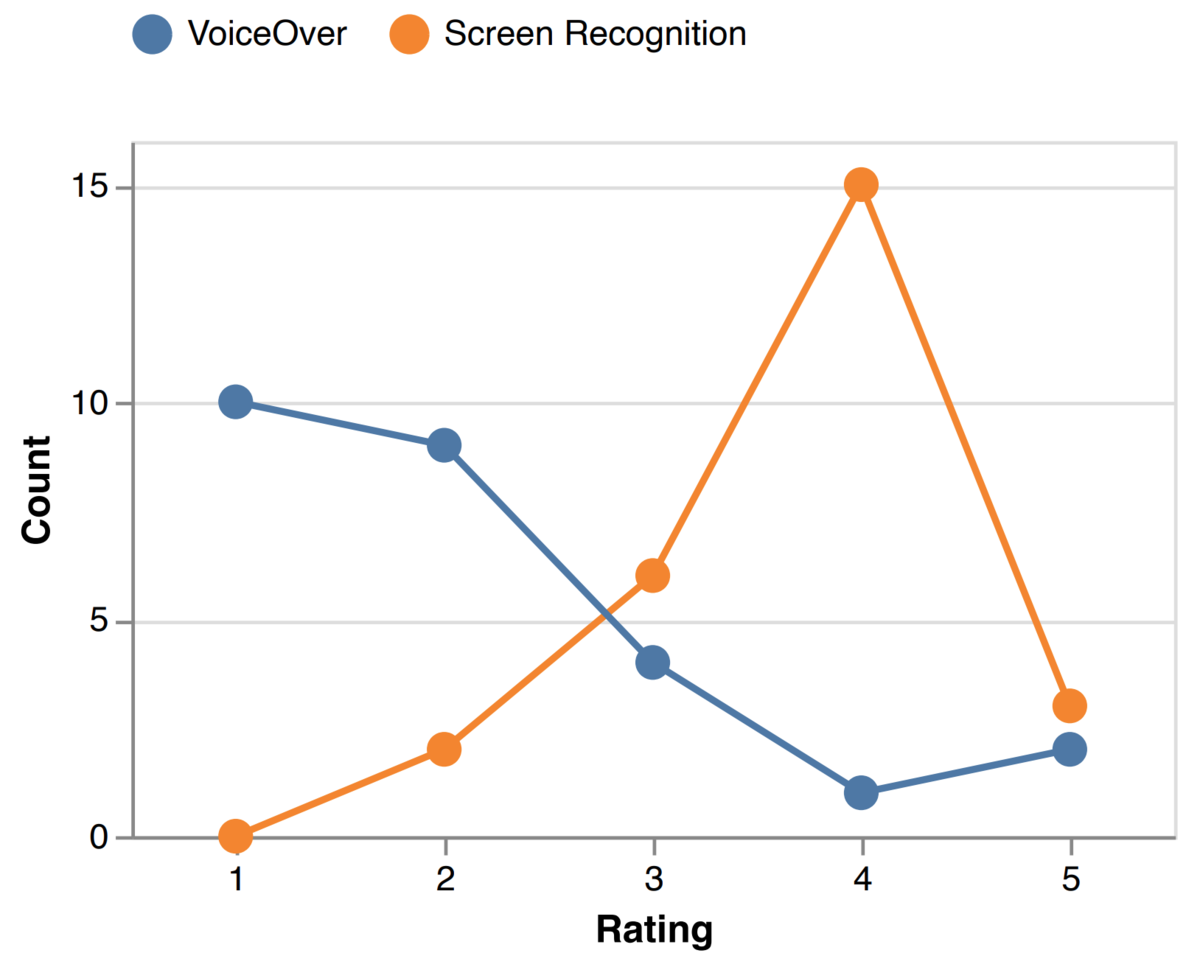 (論文より画像引用)
(論文より画像引用)
青は既存のVoiceOverで提案手法はオレンジとなります。 提案手法のほうが明らかに評価が高いことが分かります。 また、ゲームのようなVoiceOverがほとんど使えないアプリも遊ぶことができているようです。
まだ完全な精度で検出ができているとは言えませんが、VoiceOverがほとんど動作しないアプリに対しては、非常に大きい効果が出ていると言えます。
まとめ
本記事では、機械学習を使ってアクセシビリティ機能を補完する研究を紹介しました。 実験では、実際にVoiceOverを必要とするユーザに使ってもらい、適切に補完ができていることが分かりました。
いわゆるディープラーニングを用いて華麗にUIを検出しているのですが、それだけでは達成できない精度の部分はヒューリスティックな方法 (tintColorやUIの位置情報を使ったり) で改善しているのが印象的でした。
この研究はアクセシビリティ機能にフォーカスしていますが、スクリーンショットからUIを認識するという技術はアクセシビリティ機能以外にも応用が可能と考えられます。 例えば、開発者がアプリを開発している中で機械がUIについての提案を行ったり、UIの自動操作にも使えるかもしれません。
また、スクリーンショットからUIを検出するという手法はiOSアプリに依存していないので、AndroidアプリやWebなどの別のプラットフォームにも応用可能と論文では述べています。
UIデザインというと、機械学習からは遠い人間のフィールドというイメージがありますが、将来的には人と機械が連携しながらより良いアプリを開発していく、という未来が来るかもしれません。
さて、本記事はアドベントカレンダー2日目でしたが、明日はtakaoさんの記事「delyで働くパパエンジニアの日常を紹介」です。お楽しみに。
delyではエンジニア、デザイナー、PdMを積極採用しています。 少しでも興味がありましたら、お話だけでもできればと思います。