
Hello, my name is Niko, and I am currently working in Kurashiru's data enabling team as a newly joined data engineer. While I'm enthusiastic about learning Japanese, my proficiency with Japanese particles is still a work in progress (笑). For this reason, I have decided to write this blog in English.
Preface
At Kurashiru, we use dbt (data build tools) as our platform to handle data transformations from the data lake to our data warehouse. dbt is a helpful set of tools and frameworks that let us create transformation queries in line with software engineering principles. Gone are the days of dealing with complicated queries on our data platform. With dbt, we can manage and "engineer" our data just like regular software development.
Since we started using dbt, our productivity in data modeling has significantly improved, which we find very beneficial. dbt also provides us with useful tools like "slim CI" for Continuous Integration. In this blog, I'll explain what SLIM CI is and why it's essential for our workflow. If you want to know more about dbt, you can explore the official documentation here:
dbt CI Job
In Continuous Integration (CI), the process involves automatically building and testing new code whenever a developer tries to merge it into the main repository. This principle applies to dbt too. When a developer makes a Pull Request (PR) in a dbt repository, it's essential to follow CI practices. Doing so helps us avoid broken queries in our Production database and maintain good code quality. Now, let's see the flow of CI job that dbt performs using an illustration:
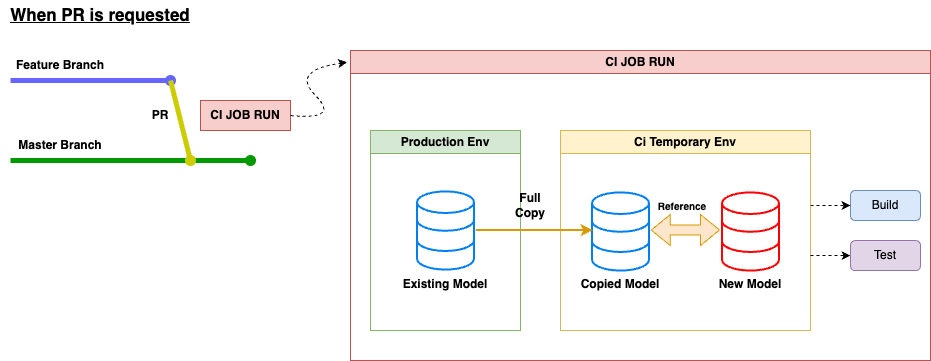
Let's imagine the Master branch codes are linked to the Production environment. When a Pull Request (PR) is made, the CI JOB will duplicate the existing data model from Production to a temporary environment. Then, it will build and test the copied model along with the changes from the PR.
So far, this process works fine for application code because it usually requires only a small amount of data for building and testing new codes. However, the problem arises when dealing with data models in data modeling works. It demands a significant amount of data and incurs high data processing costs for just one PR. Therefore, we need to find a way to improve this process and reduce the overall expenses.
Slim CI
Luckily, dbt offers us SLIM CI, which plays a crucial role in this situation. When we switch from the default CI Job to SLIM CI, our CI workflow transforms into the following:

In the new workflow, the CI Job doesn't have to copy all existing models from the Production environment for building and testing. Instead, it only creates the data model that has changed in the PR and refers to other required dependencies (like source tables or views for JOIN, UNION) already present in the production environment. This way, the process becomes much faster and more cost-effective since we only create what is necessary.
dbt's SLIM CI achieves this by using a built-in powerful feature called "defer." With "defer," a single model can be built without the need to rebuild all its dependencies in the CI temporary environment. This efficient approach saves time and resources, making the whole data modeling process smoother and more efficient.
To Defer or Not Defer
So, what is "defer"? To grasp the concept of "defer," let's first understand how dbt functions. To build our data models using dbt, we typically run this command
# first run dbt build
Under the hood, dbt will do something like this:

When we examine the final step of the dbt process, we notice that dbt always produces artifacts. These artifacts represent the most recent state of the current data models in the target database or data warehouse. Now, how does "defer" come into play? Well, "defer" uses these artifacts to check if there are any differences between the dbt runs and the existing state of the target database or data warehouse, kind of like a DIFF logic.
To enable "defer" in dbt, we can include some flags to the previously run first run command, which looks something like this:
# second run # --select state:modified # means only select changed states compared to the previous state dbt build --select state:modified --defer --state path_to_first_run_state
With this approach, dbt constantly checks the previous state and only builds models that have been changed from the successful previous run of dbt. When we include this command in a Job that triggers when a Pull Request (PR) is requested, dbt refers to it as "SLIM CI".
Example
Imagine we work at a beef bowl restaurant, and our responsibility is managing the restaurant's data. In the data warehouse's production environment (DBT_PRD), we have two models named meat and rice:

We want to create a new model called "meat_rice_menu" by combining the data from the two existing models, meat and rice. This new model will be represented in a chart like this:

default CI Job
Let's proceed with the PR and use this model plan. First, we'll run the regular dbt CI Job without defer/SLIM CI. During this process, dbt will create a new temporary schema for each PR that is being tested. Fortunately, dbt will always log the activities of the run. Here's the completion message from dbt's CI logs:

There, we can see that dbt made 2 table models and 1 view model. To make sure, let's look at our current temporary PR schema. When we check the temporary PR schema, we'll see that it did create all three models, both the parent and child models:
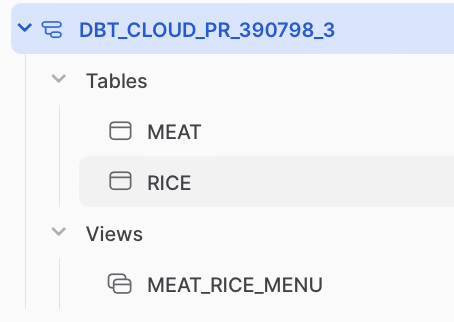
When we take a look at the definition, we can see that the newly created model was referencing the temporary schema:

SLIM CI Job
Now, let's try the PR again, but this time, we'll use defer/SLIM CI. We already have artifacts that show the current state from the production's dbt Job runs. When we run the PR job with defer/SLIM CI, let's look at the same finished log message that dbt always creates for every run:

We notice that it only created one view model. When we check the PR's temporary schema, we see that only the new model is created, which is meat_rice_menu and it didn't duplicate the existing tables:

When we see the definition again, we can see that now it referencing the production environment (DBT_PRD):

By referring directly to the production models instead of copying them, we can greatly reduce the costs of our PR. This approach avoids unnecessary duplication, and we only focus on building and testing the changes needed for the new model. As a result, the process becomes more efficient and cost-effective.
Summary
Slim CI is a powerful dbt feature that can save time and reduce costs during the build and testing of models in the CI workflow. By using defer, Slim CI can identify differences between the current data warehouse state and the changes in PR requests. This boosts our productivity since we don't have to wait long for PRs to be built and tested before merging them to the master branch.
Today, I introduced one of the powerful features of dbt in this blog. However, we don't want to stop there. In line with our commitment to continuous improvement (KAIZEN) and one of our value which is good to great, we aim to enhance our data infrastructure further. Thank you for reading this blog, and stay tuned for more data engineering adventures ahead!
References
Continuous integration in dbt Cloud | dbt Developer Hub
Using dbt Deferral to Simplify Development | Infinite Lambda